Not All Frames Are Equal: Complexity-Aware Masked Motion Generation via Motion Spectral Descriptors
* co-first authors; † corresponding author
📋 Abstract
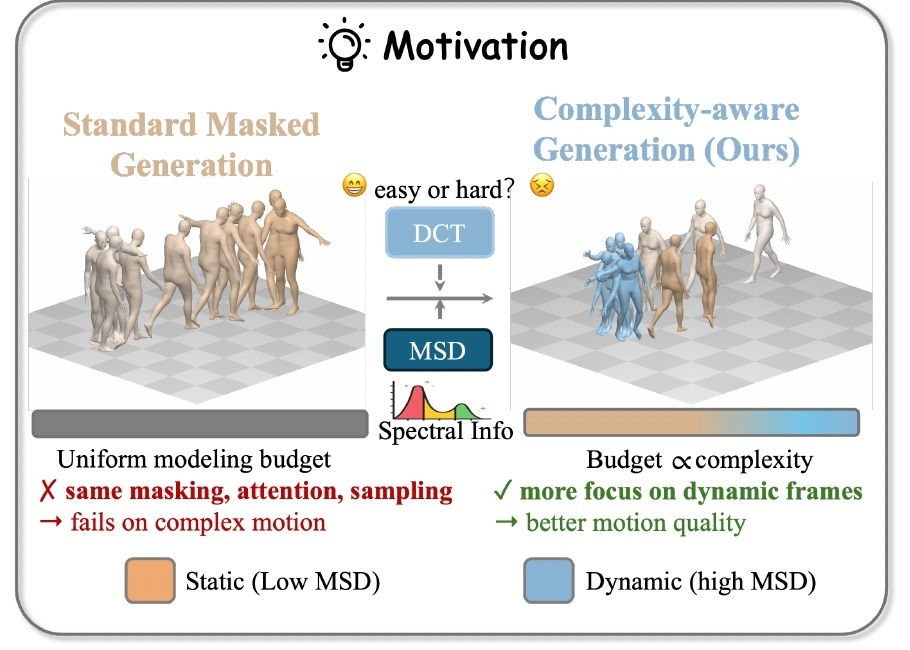
Masked generative models have become a strong paradigm for text-to-motion synthesis, but they still treat motion frames too uniformly during masking, attention, and decoding. This is a poor match for motion, where local dynamic complexity varies sharply over time. We show that current masked motion generators degrade disproportionately on dynamically complex motions, and that frame-wise generation error is strongly correlated with motion dynamics. Motivated by this mismatch, we introduce the Motion Spectral Descriptor (MSD), a simple and parameter-free measure of local dynamic complexity computed from the short-time spectrum of motion velocity. Unlike learned difficulty predictors, MSD is deterministic, interpretable, and derived directly from the motion signal itself. We use MSD to make masked motion generation complexity-aware. In particular, MSD guides content-focused masking during training, provides a spectral similarity prior for self-attention, and can additionally modulate token-level sampling during iterative decoding. Built on top of masked motion generators, our method, DynMask, improves motion generation most clearly on dynamically complex motions while also yielding stronger overall FID on HumanML3D and KIT-ML. The code is available at https://github.com/Xiangyue-Zhang/DynMask.
🎬 Video
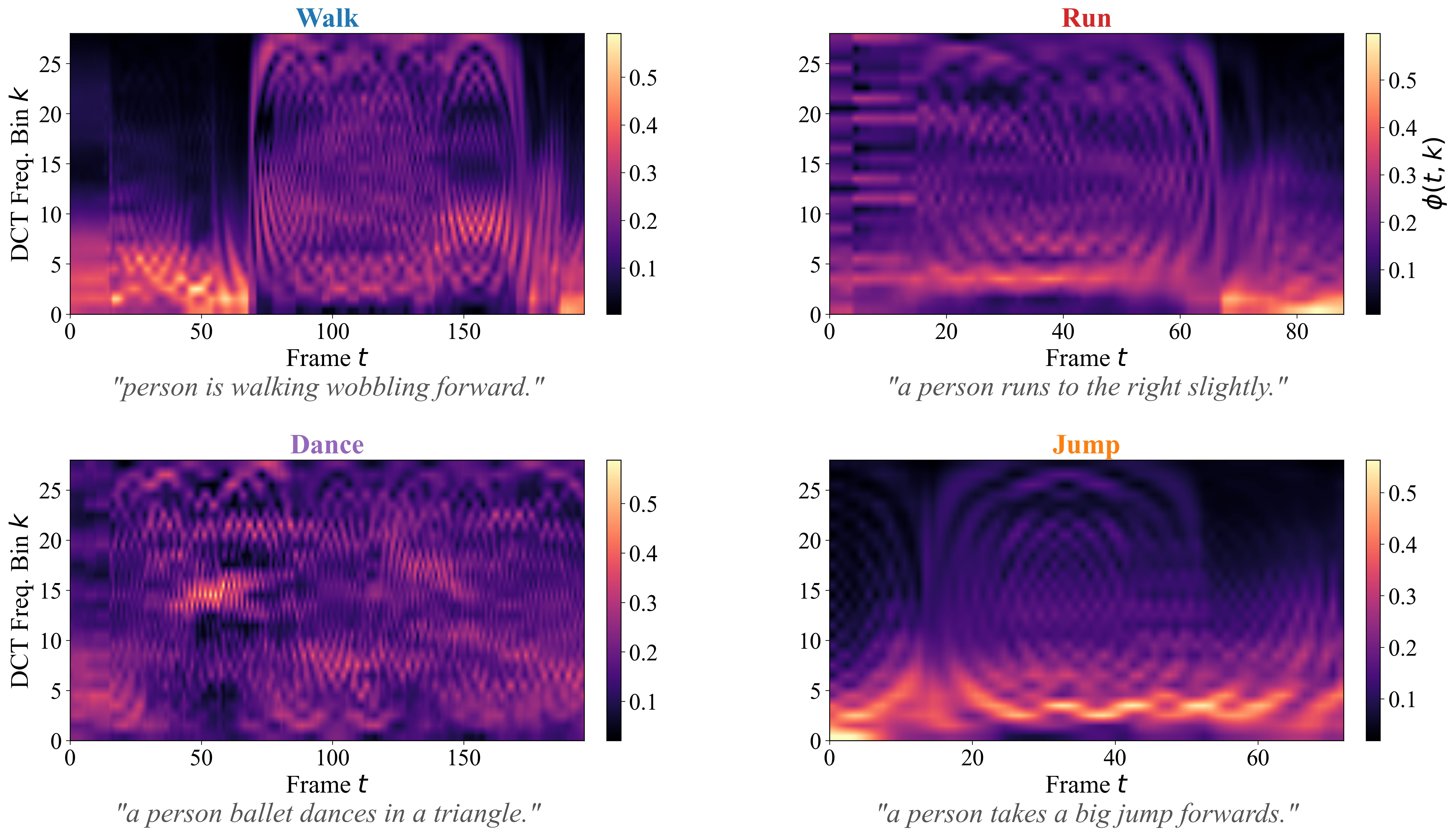
🔬 MSD Spectral Fingerprints
Representative MSD heatmaps for different motion types show distinct temporal-frequency patterns across time.
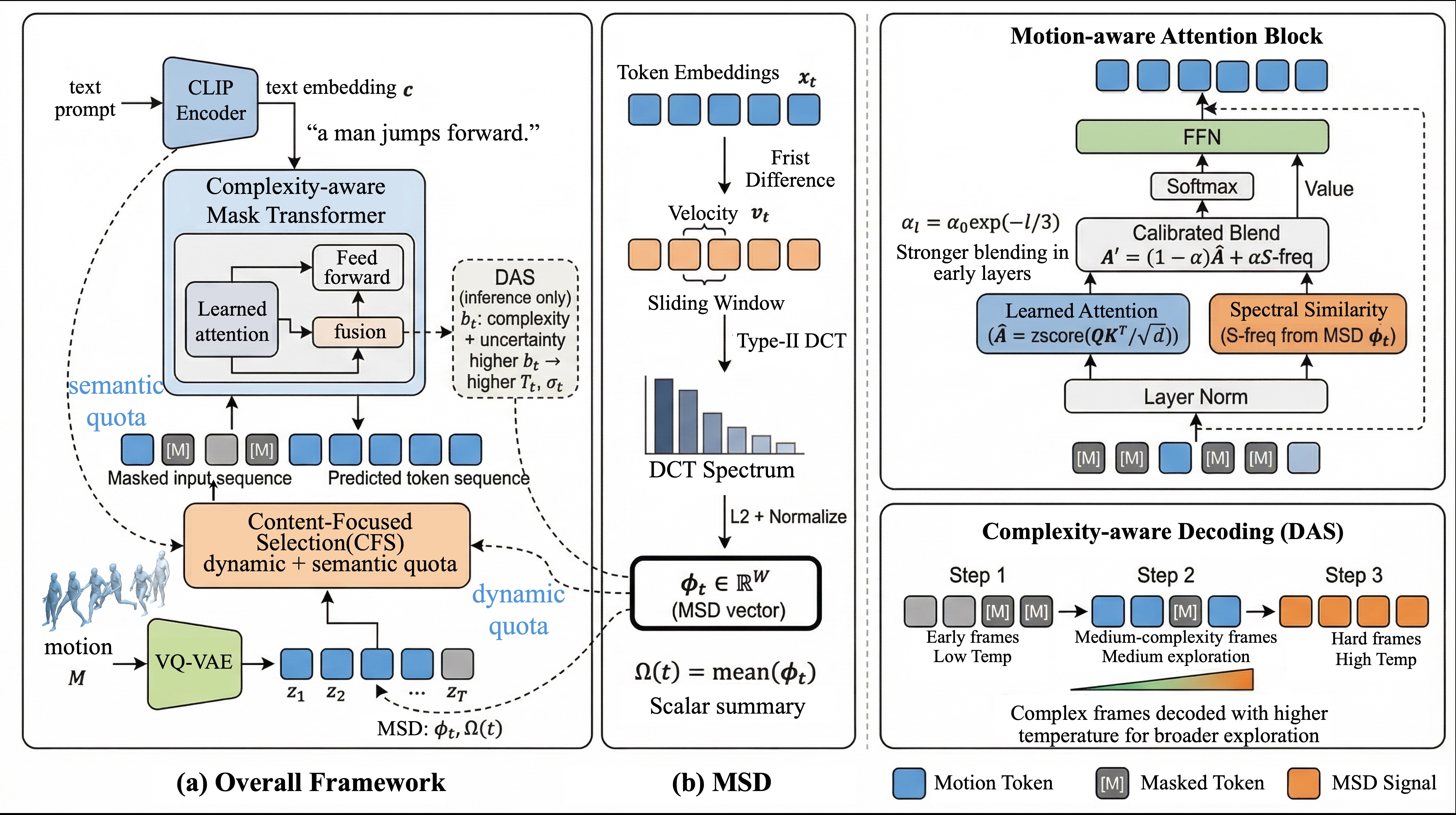
🏗️ Framework
Overview of DynMask: MSD-guided complexity-aware masked motion generation.
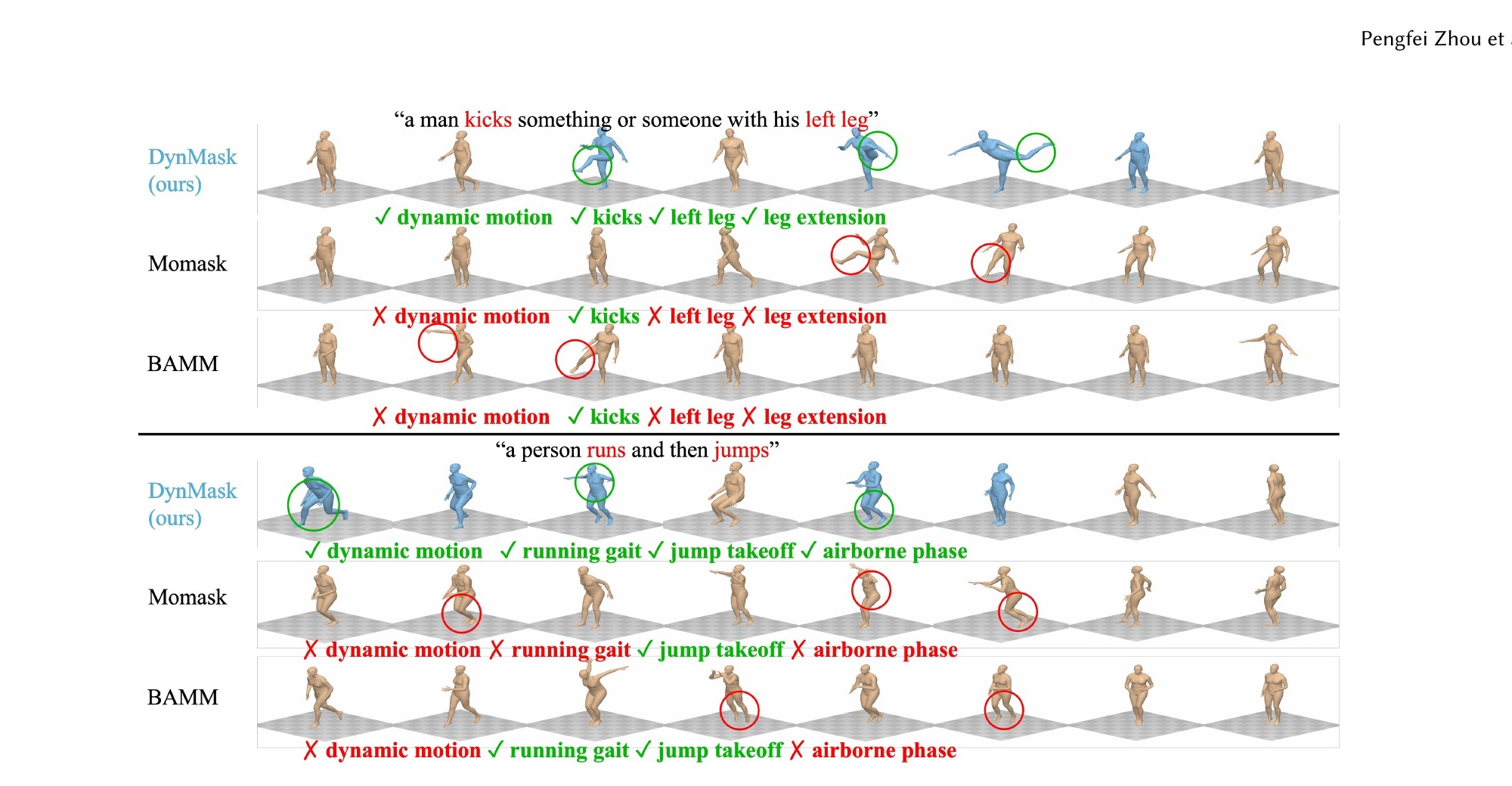
🎨 Qualitative Comparisons
Qualitative comparison on challenging dynamic prompts.
👁️ Attention Visualization
Attention visualization on a multi-phase turning-and-spinning sequence.
📊 Quantitative Results
DynMask achieves the best FID within the masked motion generation family on both HumanML3D and KIT-ML benchmarks.
📄 BibTeX
@misc{zhou2026framesequalcomplexityawaremasked,
title={Not All Frames Are Equal: Complexity-Aware Masked Motion Generation via Motion Spectral Descriptors},
author={Pengfei Zhou and Xiangyue Zhang and Xukun Shen and Yong Hu},
year={2026},
eprint={2603.29655},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2603.29655},
}