EchoMask: Speech-Queried Attention-based Mask Modeling for Holistic Co-Speech Motion Generation
Abstract
Masked modeling framework has shown promise in co-speech motion generation. However, it struggles to identify semantically significant frames for effective motion masking. In this work, we propose a speech-queried attention-based mask modeling framework for co-speech motion generation. Our key insight is to leverage motion-aligned speech features to guide the masked motion modeling process, selectively masking rhythm-related and semantically expressive motion frames. Specifically, we first propose a motion-audio alignment module (MAM) to construct a latent motion-audio joint space. In this space, both low-level and high-level speech features are projected, enabling motion-aligned speech representation using learnable speech queries. Then, a speech-queried attention mechanism (SQA) is introduced to compute frame-level attention scores through interactions between motion keys and speech queries, guiding selective masking toward motion frames with high attention scores. Finally, the motion-aligned speech features are also injected into the generation network to facilitate co-speech motion generation. Qualitative and quantitative evaluations confirm that our method outperforms existing state-of-the-art approaches, successfully producing high-quality co-speech motion. The code will be released at https://github.com/Xiangyue-Zhang/EchoMask.
Demo
Masking Problem
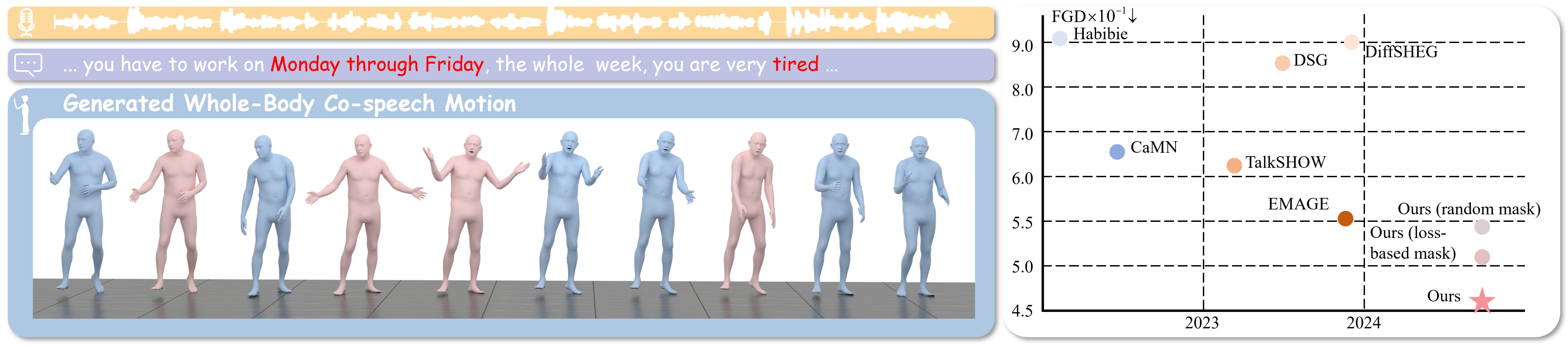
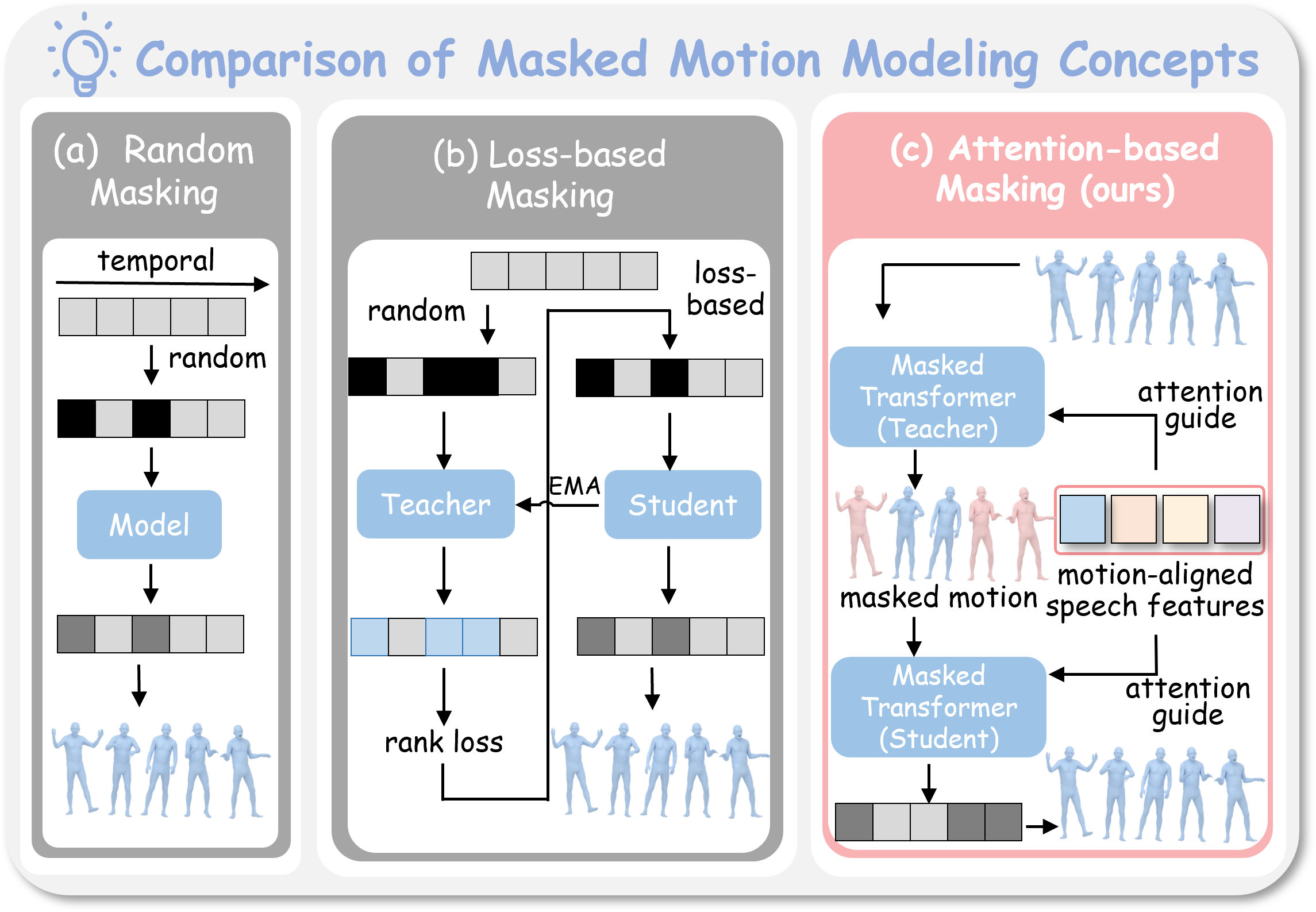
The main question is where masking should happen. Random masking is blind, and loss-based masking can over-focus on hard but uninformative transitions. EchoMask uses speech as the query signal.
Method
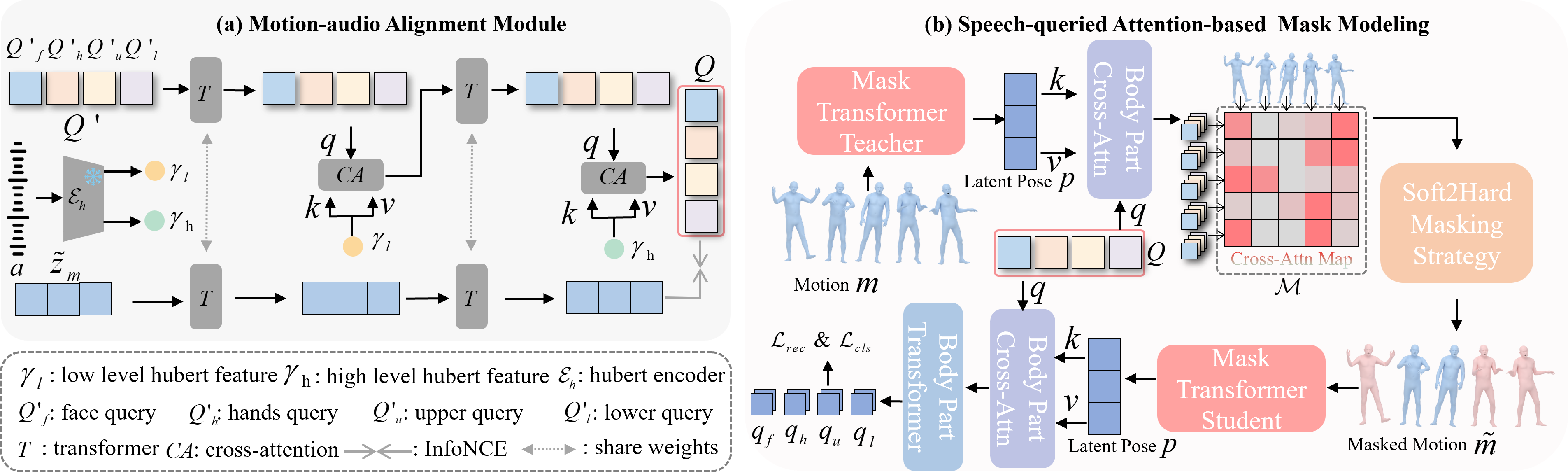
EchoMask first aligns audio and motion in a shared latent space, then uses speech-queried attention to decide which motion frames should be masked and reconstructed.
Qualitative Results
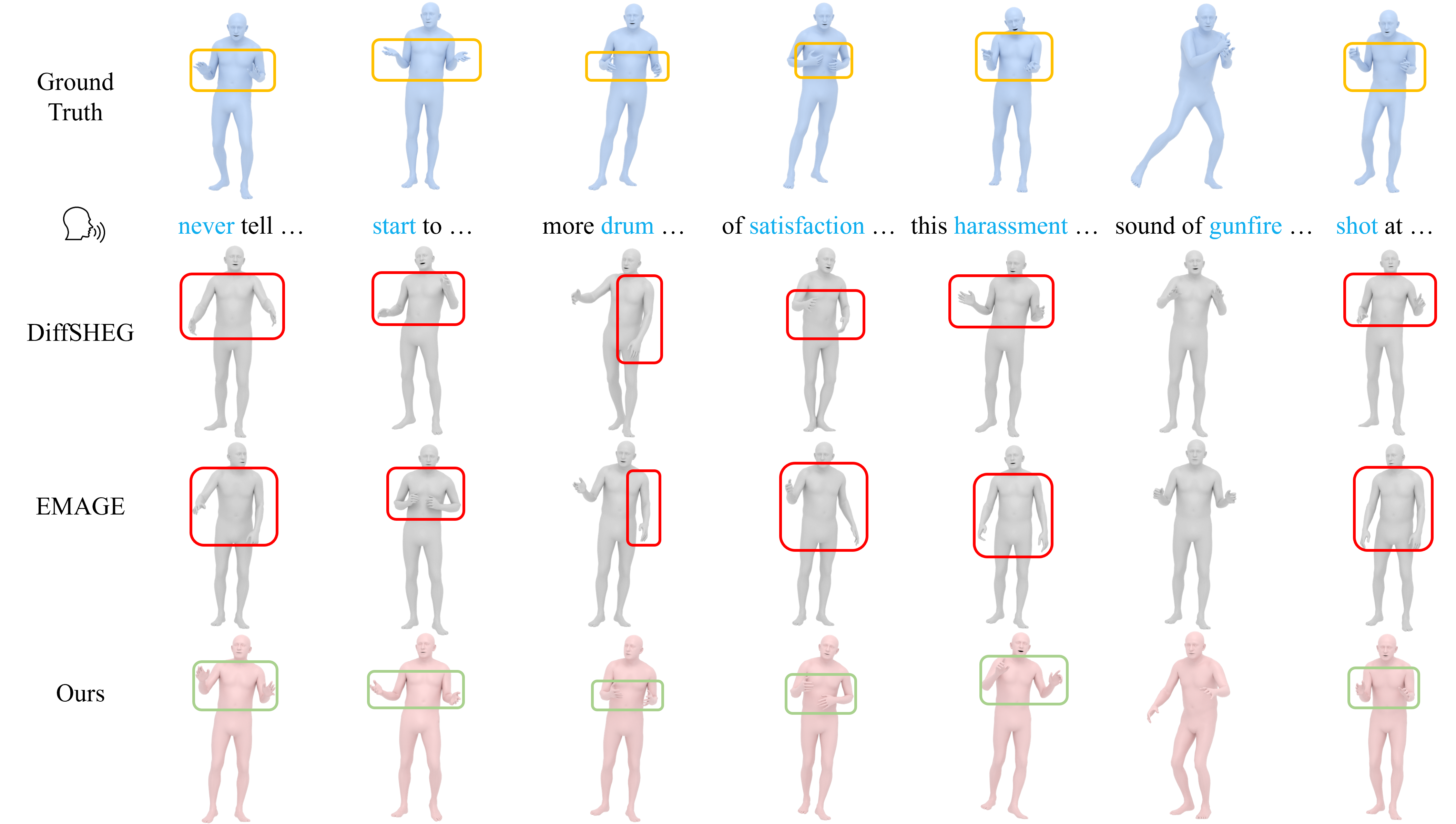
The examples show that speech-guided masking improves both body gestures and facial articulation, especially where semantic cues should trigger clearer motion.

Quantitative Results
Lower is better for FGD, MSE, and LVD; higher is better for BC and DIV. EchoMask gives the best holistic score on most metrics while remaining competitive in diversity.
| Setting | Method | FGD lower | BC higher | DIV higher | MSE lower | LVD lower |
|---|---|---|---|---|---|---|
| Facial | FaceFormer | - | - | - | 7.787 | 7.593 |
| Facial | CodeTalker | - | - | - | 8.026 | 7.766 |
| Non-facial | DisCo | 9.680 | 6.441 | 9.892 | - | - |
| Non-facial | HA2G | 12.14 | 6.711 | 8.916 | - | - |
| Non-facial | CaMN | 6.644 | 6.769 | 10.86 | - | - |
| Non-facial | LivelySpeaker | 11.80 | 6.659 | 11.28 | - | - |
| Non-facial | DSG | 8.811 | 7.241 | 11.49 | - | - |
| Holistic | Habibie et al. | 9.040 | 7.716 | 8.213 | 8.614 | 8.043 |
| Holistic | TalkSHOW | 6.209 | 6.947 | 13.47 | 7.791 | 7.771 |
| Holistic | EMAGE | 5.512 | 7.724 | 13.06 | 7.680 | 7.556 |
| Holistic | DiffSHEG | 8.986 | 7.142 | 11.91 | 7.665 | 8.673 |
| Holistic | EchoMask | 4.623 | 7.738 | 13.37 | 6.761 | 7.290 |
BibTeX
@inproceedings{zhang2025echomask,
title={EchoMask: Speech-Queried Attention-based Mask Modeling for Holistic Co-Speech Motion Generation},
author={Zhang, Xiangyue and Li, Jianfang and Zhang, Jiaxu and Ren, Jianqiang and Bo, Liefeng and Tu, Zhigang},
booktitle={Proceedings of the 33rd ACM International Conference on Multimedia},
pages={10827--10836},
year={2025}
}