Mitigating Error Accumulation in Co-Speech Motion Generation via Global Rotation Diffusion and Multi-Level Constraints
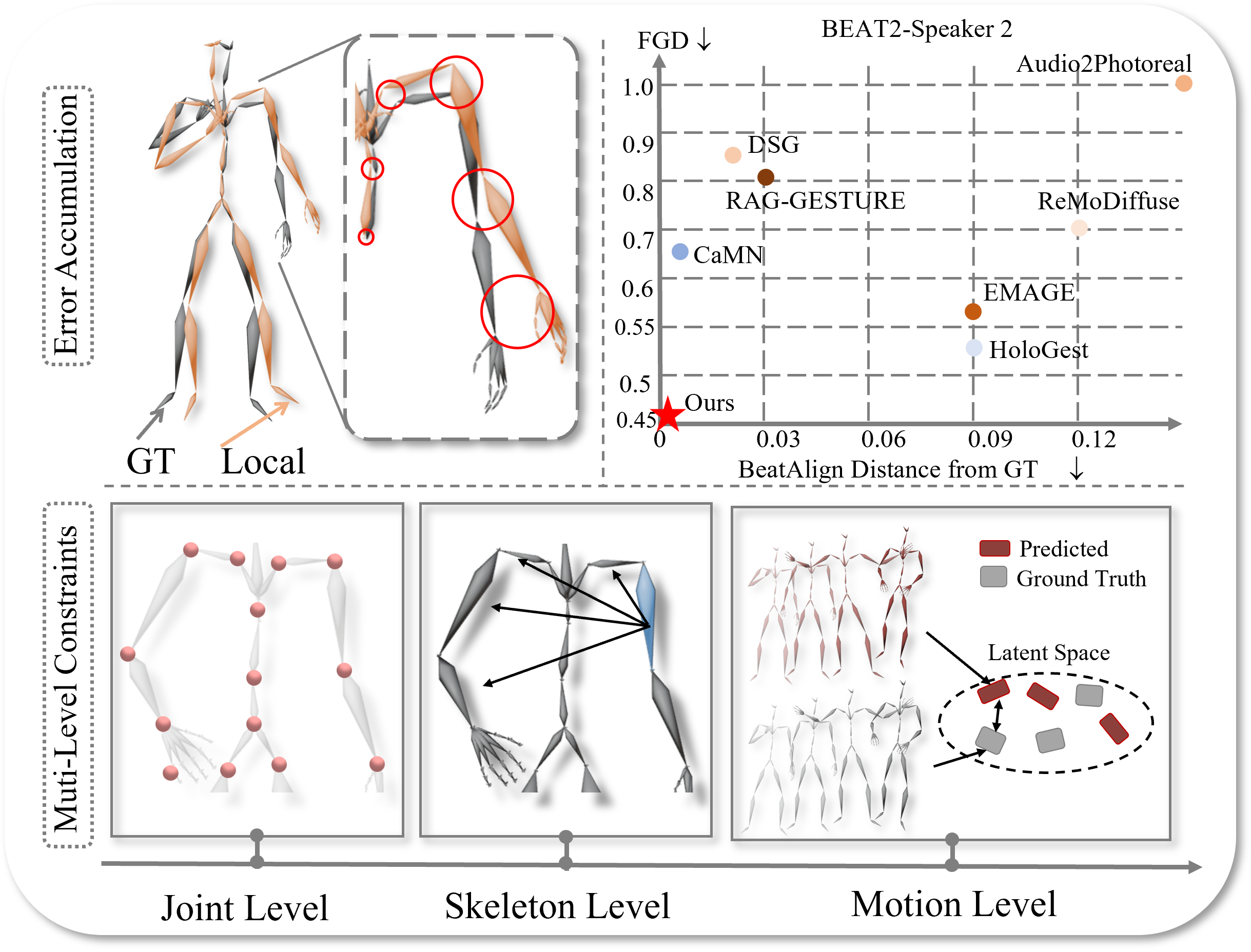
Abstract
Reliable co-speech motion generation requires precise motion representation and consistent structural priors across all joints. Existing generative methods typically operate on local joint rotations, which are defined hierarchically based on the skeleton structure. This leads to cumulative errors during generation, manifesting as unstable and implausible motions at end-effectors. In this work, we propose GlobalDiff, a diffusion-based framework that operates directly in the space of global joint rotations for the first time, fundamentally decoupling each joint's prediction from upstream dependencies and alleviating hierarchical error accumulation. To compensate for the absence of structural priors in global rotation space, we introduce a multi-level constraint scheme. Specifically, a joint structure constraint introduces virtual anchor points around each joint to better capture fine-grained orientation. A skeleton structure constraint enforces angular consistency across bones to maintain structural integrity. A temporal structure constraint utilizes a multi-scale variational encoder to align the generated motion with ground-truth temporal patterns. These constraints jointly regularize the global diffusion process and reinforce structural awareness. Extensive evaluations on standard co-speech benchmarks show that GlobalDiff generates smooth and accurate motions, improving the performance by 46.0% compared to the current SOTA under multiple speaker identities. The code will be released at https://github.com/Xiangyue-Zhang/GlobalDiff.
Demo
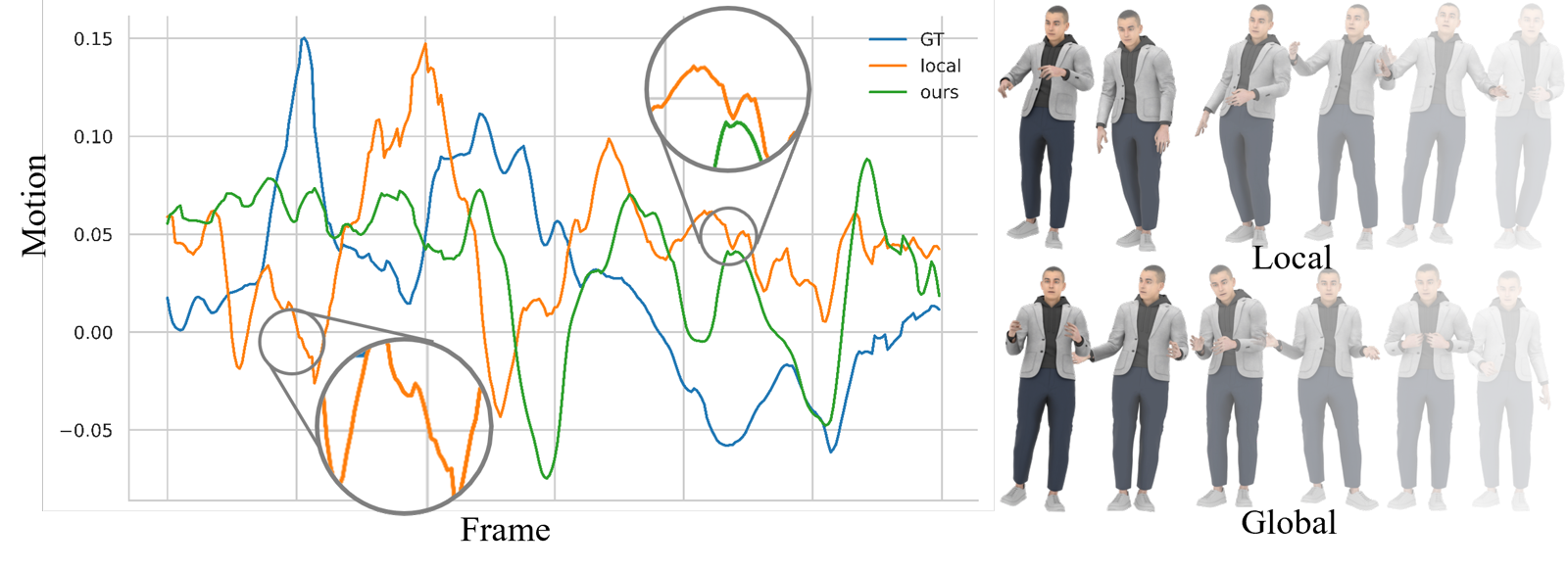
Representation Shift
GlobalDiff first changes the motion representation. Instead of predicting local rotations along the kinematic tree, it predicts each joint in global rotation space so downstream joints are not forced to inherit upstream mistakes.
Method
The method is not only a new rotation parameterization. GlobalDiff pairs global diffusion with structure-aware losses so the model remains anatomically plausible.
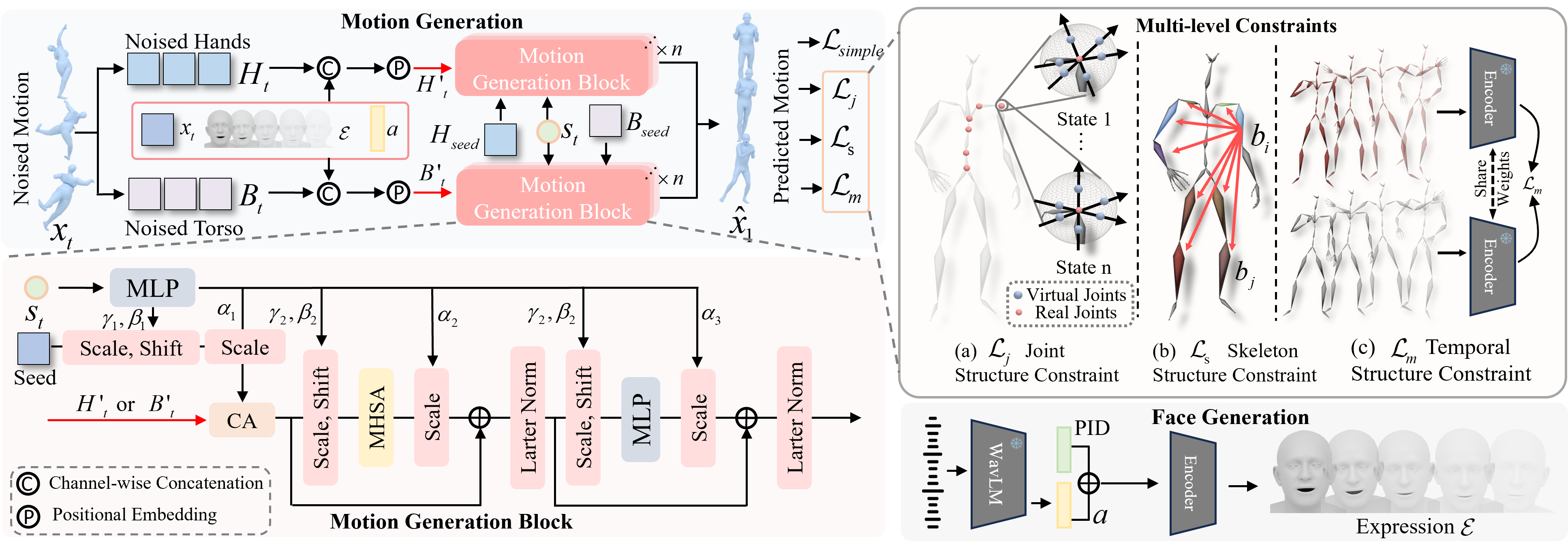
Structural Constraints
Because global rotations remove the skeleton hierarchy, the model needs explicit structural guidance. The constraints below make the generated motion respect local joint orientation, bone-angle consistency, and temporal dynamics.

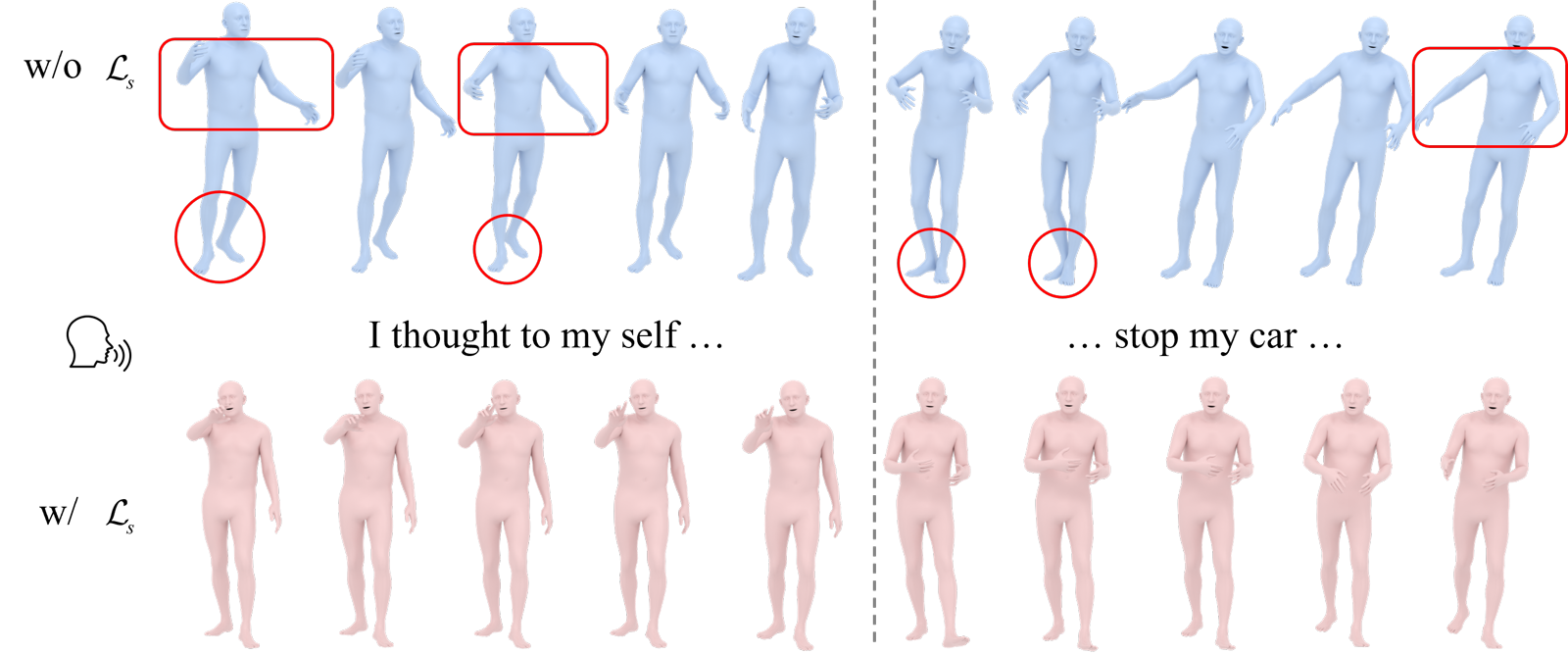
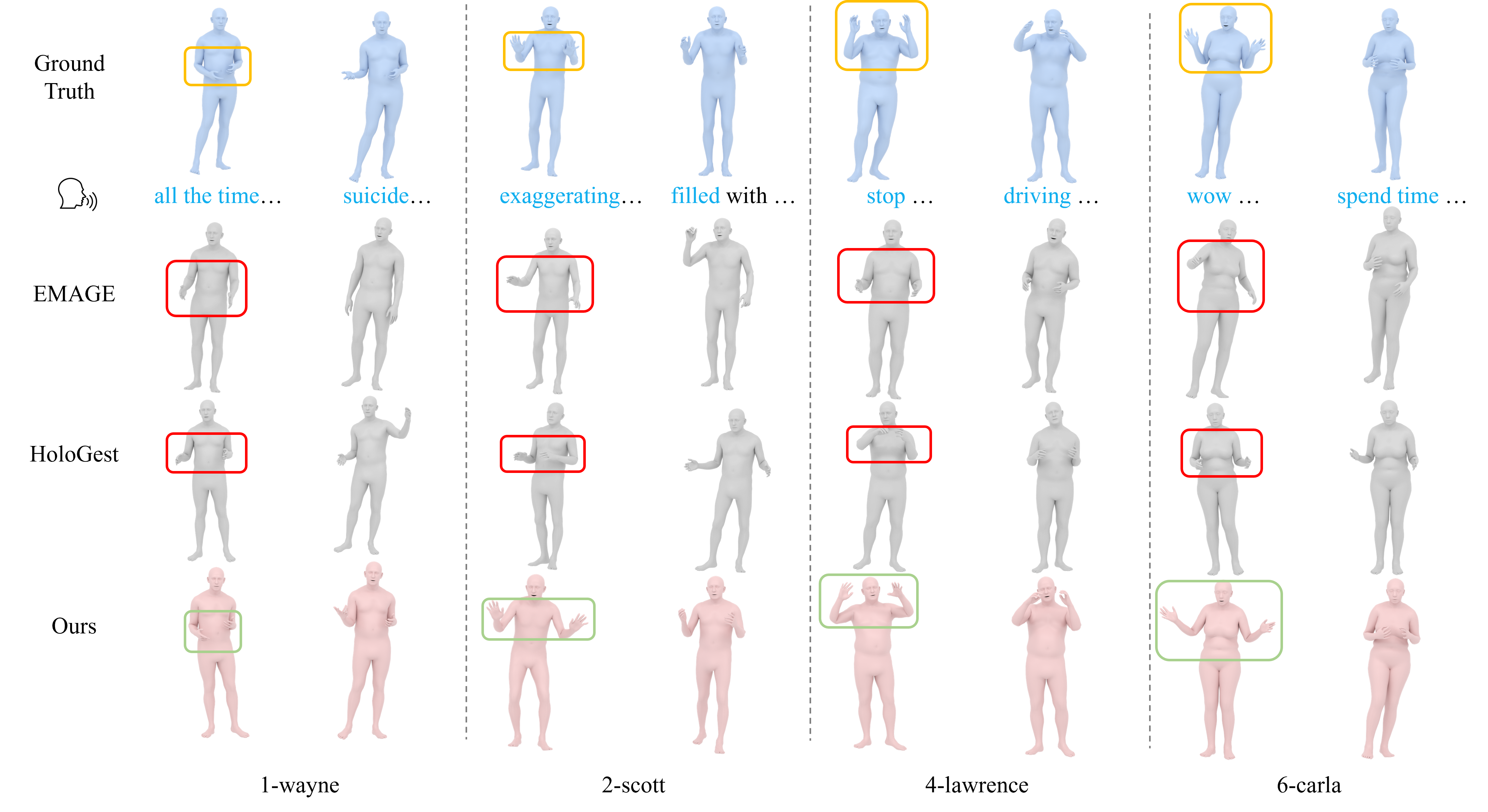
Qualitative Results
The visual examples show the main benefit of the representation shift: hands and arms stay spatially coherent even when the utterance requires large expressive movement.
Quantitative Results
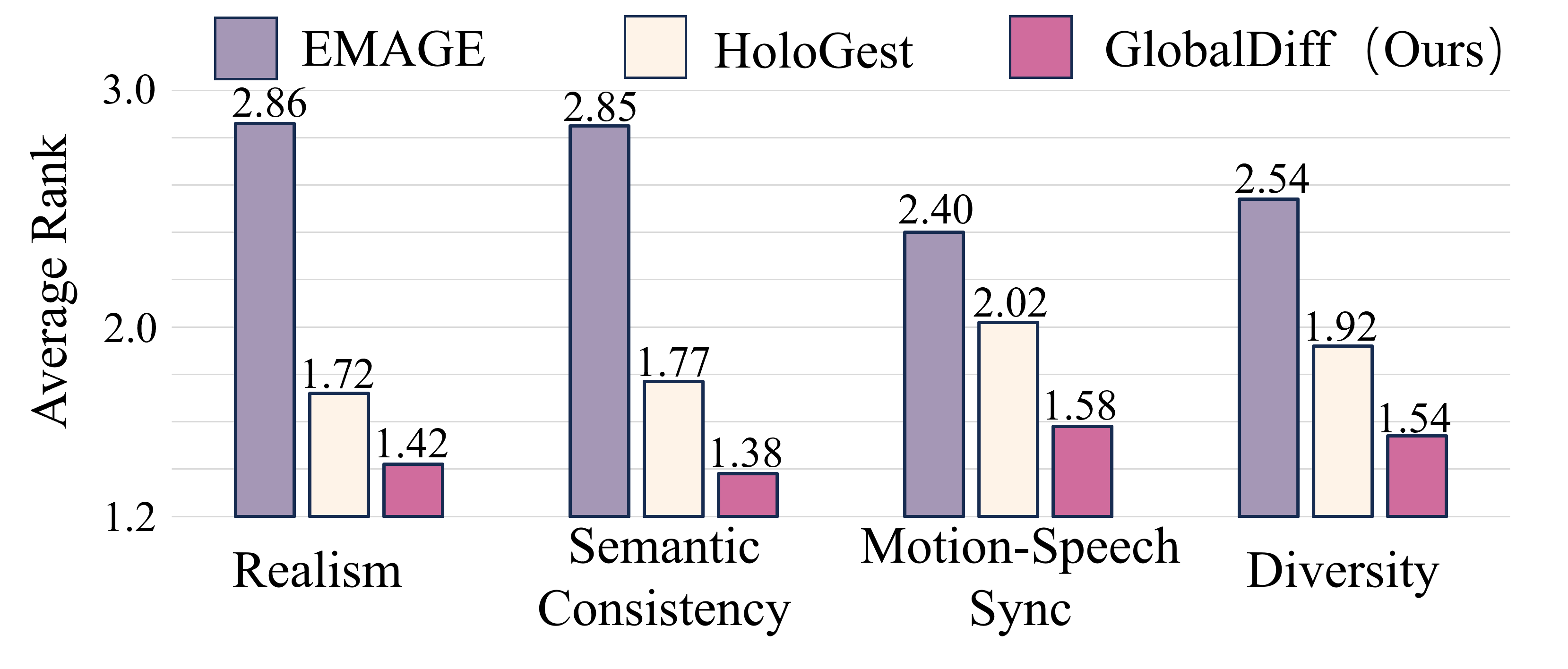
The multi-speaker setting is the key stress test because it exposes whether the representation handles different identities. GlobalDiff achieves the best all-speaker FGD and MSE while keeping beat alignment close to ground truth.
| Method | FGD lower | BeatAlign near GT | Diversity near GT | MSE lower |
|---|---|---|---|---|
| GT | - | 0.703 | 11.97 | - |
| CaMN | 0.604 | 0.711 | 9.97 | - |
| Audio2Photoreal | 1.02 | 0.550 | 12.47 | - |
| ReMoDiffuse | 0.702 | 0.824 | 12.46 | - |
| DSG | 0.881 | 0.724 | 11.49 | - |
| HoloGest | 0.534 | 0.795 | 14.15 | - |
| EMAGE | 0.570 | 0.793 | 11.41 | 7.680 |
| SemTalk | 0.428 | 0.777 | 12.91 | 6.153 |
| RAG-GESTURE | 0.808 | 0.734 | 11.97 | - |
| GlobalDiff | 0.478 | 0.705 | 13.73 | 6.330 |
| Method | FGD lower | BeatAlign near GT | Diversity near GT | MSE lower |
|---|---|---|---|---|
| GT | - | 0.477 | 7.29 | - |
| CaMN | 0.512 | 0.200 | 5.58 | - |
| Audio2Photoreal | 0.849 | 0.326 | 6.24 | - |
| ReMoDiffuse | 1.120 | 0.218 | 5.06 | - |
| DSG | 1.174 | 0.734 | 11.12 | - |
| HoloGest | 0.646 | 0.803 | 13.53 | - |
| EMAGE | 0.692 | 0.284 | 6.06 | 6.908 |
| GlobalDiff | 0.263 | 0.404 | 8.24 | 4.144 |
BibTeX
@misc{zhang2025mitigatingerroraccumulationcospeech,
title={Mitigating Error Accumulation in Co-Speech Motion Generation via Global Rotation Diffusion and Multi-Level Constraints},
author={Xiangyue Zhang and Jianfang Li and Jianqiang Ren and Jiaxu Zhang},
year={2025},
eprint={2511.10076},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2511.10076},
}