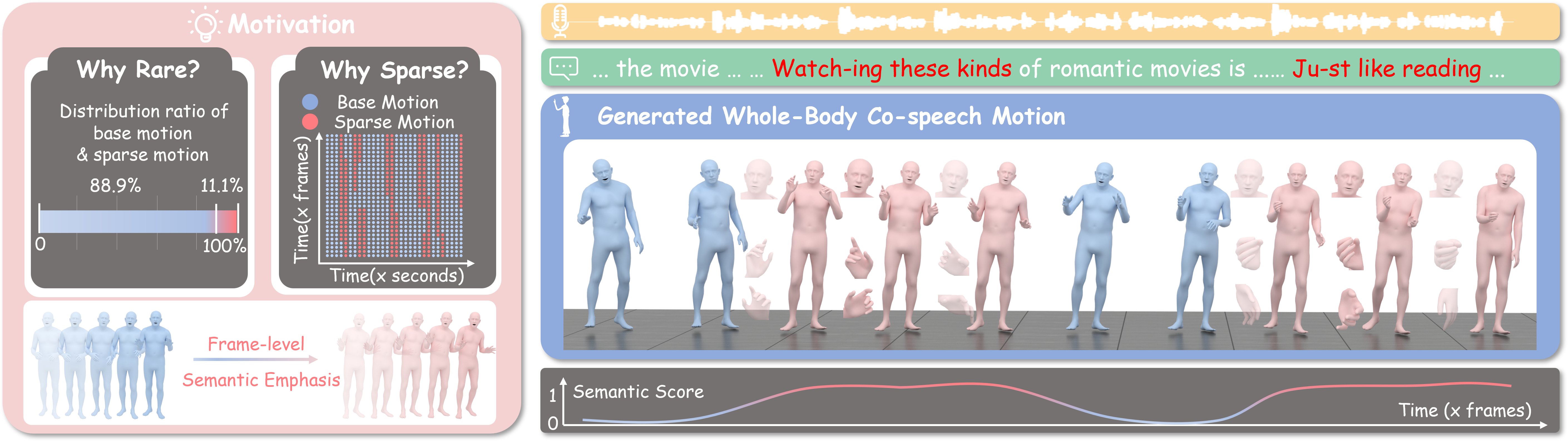
A good co-speech motion generation cannot be achieved without a careful integration of common rhythmic motion and rare yet essential semantic motion. In this work, we propose SemTalk for holistic co-speech motion generation with frame-level semantic emphasis. Our key insight is to separately learn general motions and sparse motions, and then adaptively fuse them. In particular, rhythmic consistency learning is explored to establish rhythm-related base motion, ensuring a coherent foundation that synchronizes gestures with the speech rhythm. Subsequently, semantic emphasis learning is designed to generate semantic-aware sparse motion, focusing on frame-level semantic cues. Finally, to integrate sparse motion into the base motion and generate semantic-emphasized co-speech gestures, we further leverage a learned semantic score for adaptive synthesis. Qualitative and quantitative comparisons on two public datasets demonstrate that our method outperforms the state-of-the-art, delivering high-quality co-speech motion with enhanced semantic richness over a stable base motion . The code will be released at https://github.com/Xiangyue-Zhang/SemTalk.
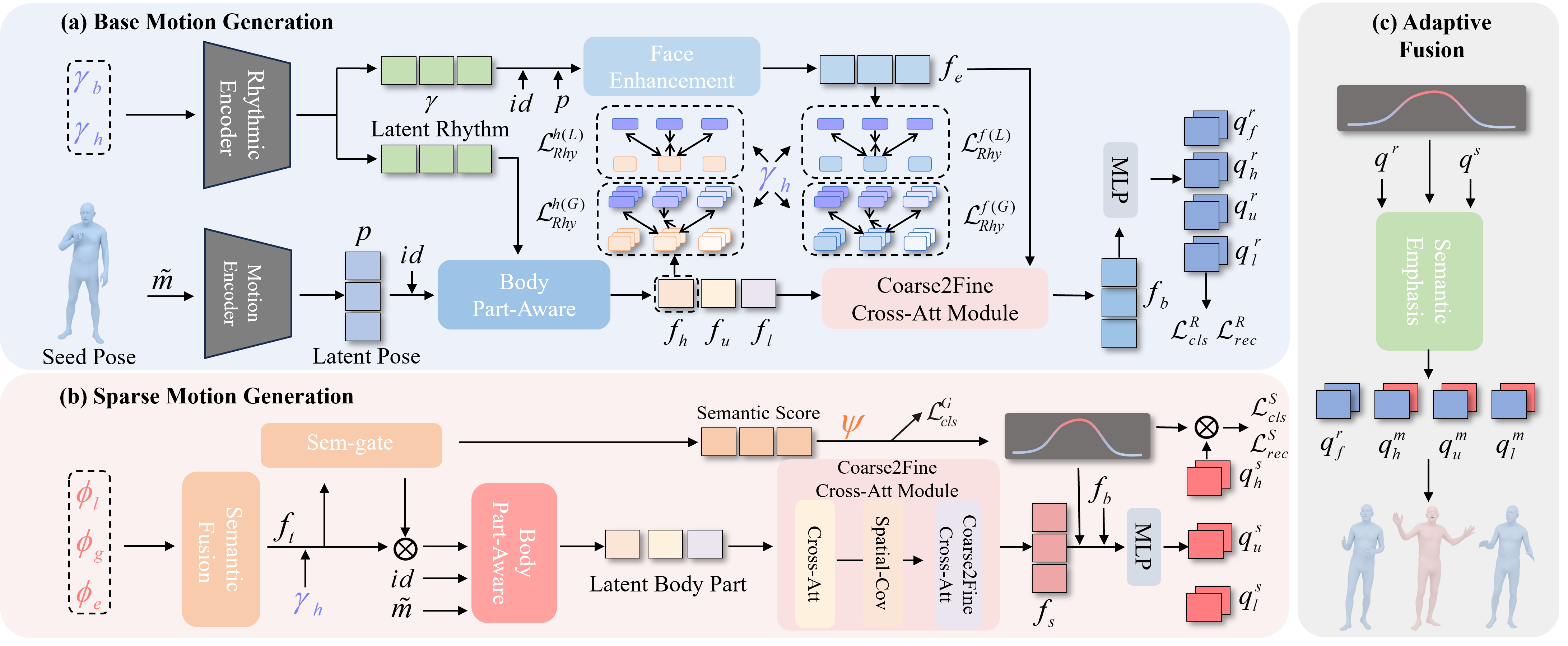
Architecture of SemTalk. SemTalk generates holistic co-speech motion in three stages. (a) Base Motion Generation uses rhythmic consistency learning to produce rhythm-aligned codes \( q^r \), conditioned on rhythmic features \( \gamma_b \), \( \gamma_h \), seed pose \( \tilde{m} \), and \( id \). (b) Sparse Motion Generation employs semantic emphasis learning to generate semantic codes \( q^s \), activated by semantic score \( \psi \). (c) Adaptively Fusion automatically combines \( q^r \) and \( q^s \) based on \( \psi \) to produce mixed codes \( q^m \) at frame level for rhythmically aligned and contextually rich motions.
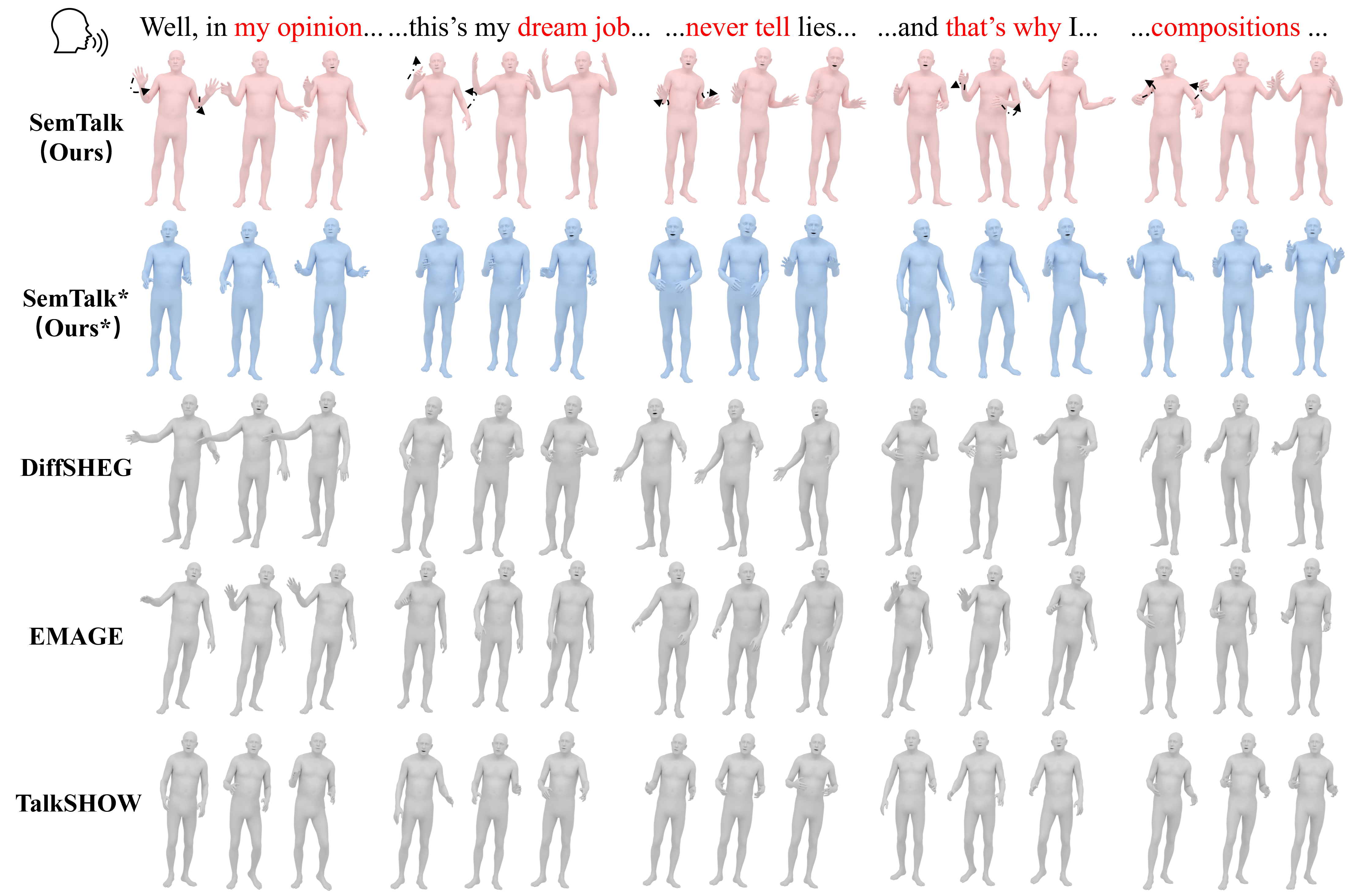
Comparison on BEAT2 Dataset. SemTalk* refers to the model trained solely on the Base Motion Generation stage, capturing basic rhythmic alignment but lacking detailed semantic gestures. In contrast, SemTalk successfully emphasized sparse yet vivid motions. For example, when the phrase “my opinion” is spoken, SemTalk-driven characters raise both hands and then make the gesture of extending their index finger to emphasize the statement. When speaking “never tell,” our model produces a clear, repeated gesture to match the rhythm of each word, capturing the intended emphasis.
Comparison on SHOW Dataset. SemTalk shows more agile gestures than TalkSHOW, EMAGE, and DiffSHEG, when applied to unseen data. Our method captures natural and contextually rich gestures, particularly in moments of emphasis such as “I like to do” and “relaxing,” where our model produces lively hand and body movements that align with the speech content. Unlike baselines, which tend to generate repetitive or overly simplistic motions, SemTalk maintains a high degree of diversity and subtlety, producing gestures that vary naturally across different phrases.

Facial Comparison on the BEAT2 Dataset. Our approach synchronizes facial expressions closely with phonetic and semantic cues in speech, generating natural lip movements that enhance clarity and expressiveness, as seen in words like "always" and "because," where each syllable transition is smoothly captured in alignment with the audio input.

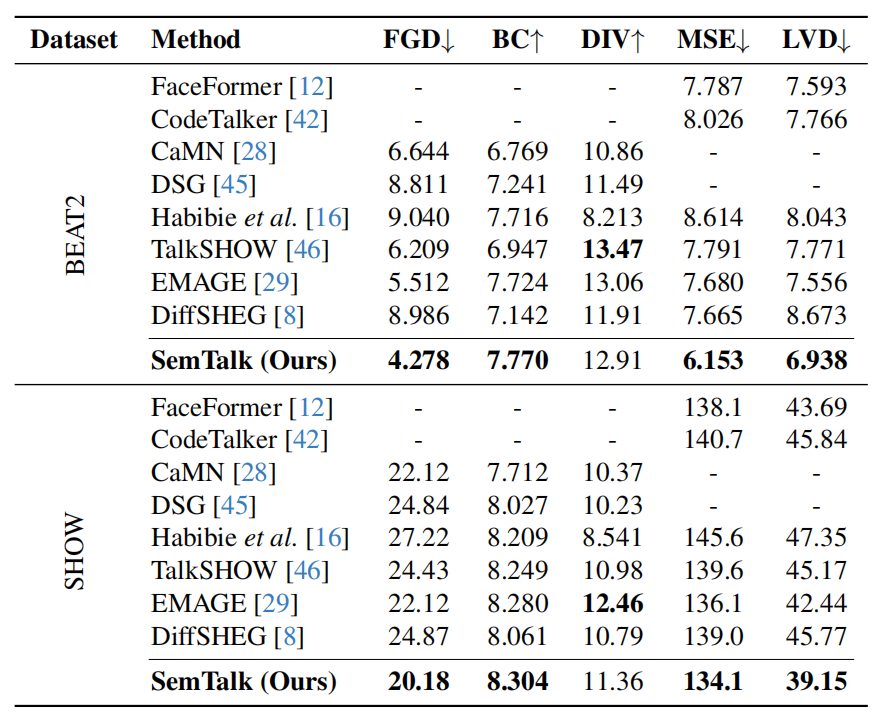
Quantitative comparison with SOTA methods. Our SemTalk method consistently outperforms state-of-the-art baselines across both the BEAT2 and SHOW datasets. Lower values are better for FMD, FGD, MSE, and LVD. Higher values are better for BC and DIV. We report FGD\(\times10^-1\), BC\(\times10^-1\), MSE\(\times10^-8\) and LVD\(\times10^-5\) for simplify.
@inproceedings{zhang2025semtalk,
title={SemTalk: Holistic Co-speech Motion Generation with Frame-level Semantic Emphasis},
author={Zhang, Xiangyue and Li, Jianfang and Zhang, Jiaxu and Dang, Ziqiang and Ren, Jianqiang and Bo, Liefeng and Tu, Zhigang},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={13761--13771},
year={2025}
}</html>