SemTalk: Holistic Co-speech Motion Generation with Frame-level Semantic Emphasis
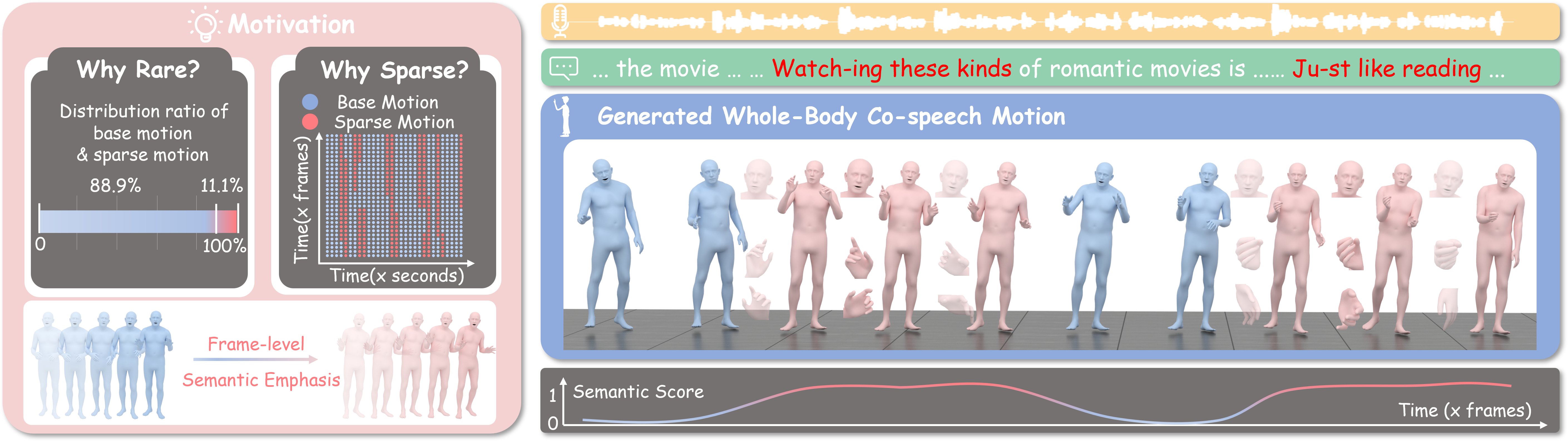
Abstract
A good co-speech motion generation cannot be achieved without a careful integration of common rhythmic motion and rare yet essential semantic motion. In this work, we propose SemTalk for holistic co-speech motion generation with frame-level semantic emphasis. Our key insight is to separately learn general motions and sparse motions, and then adaptively fuse them. In particular, rhythmic consistency learning is explored to establish rhythm-related base motion, ensuring a coherent foundation that synchronizes gestures with the speech rhythm. Subsequently, semantic emphasis learning is designed to generate semantic-aware sparse motion, focusing on frame-level semantic cues. Finally, to integrate sparse motion into the base motion and generate semantic-emphasized co-speech gestures, we further leverage a learned semantic score for adaptive synthesis. Qualitative and quantitative comparisons on two public datasets demonstrate that our method outperforms the state-of-the-art, delivering high-quality co-speech motion with enhanced semantic richness over a stable base motion. The code will be released at https://github.com/Xiangyue-Zhang/SemTalk.
Demo
Method
SemTalk uses a two-stream design: one stream learns a stable rhythm-aligned base, while another stream activates sparse semantic motion only when speech calls for emphasis.
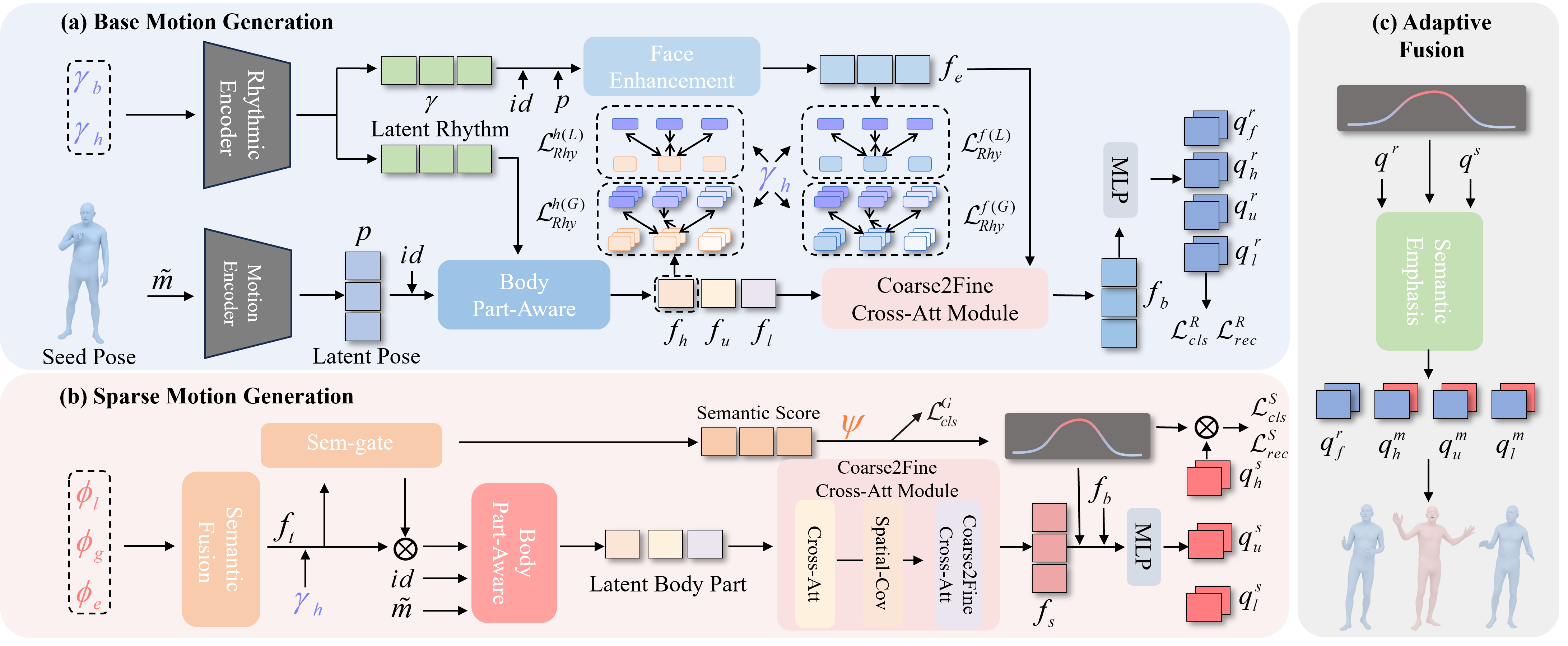
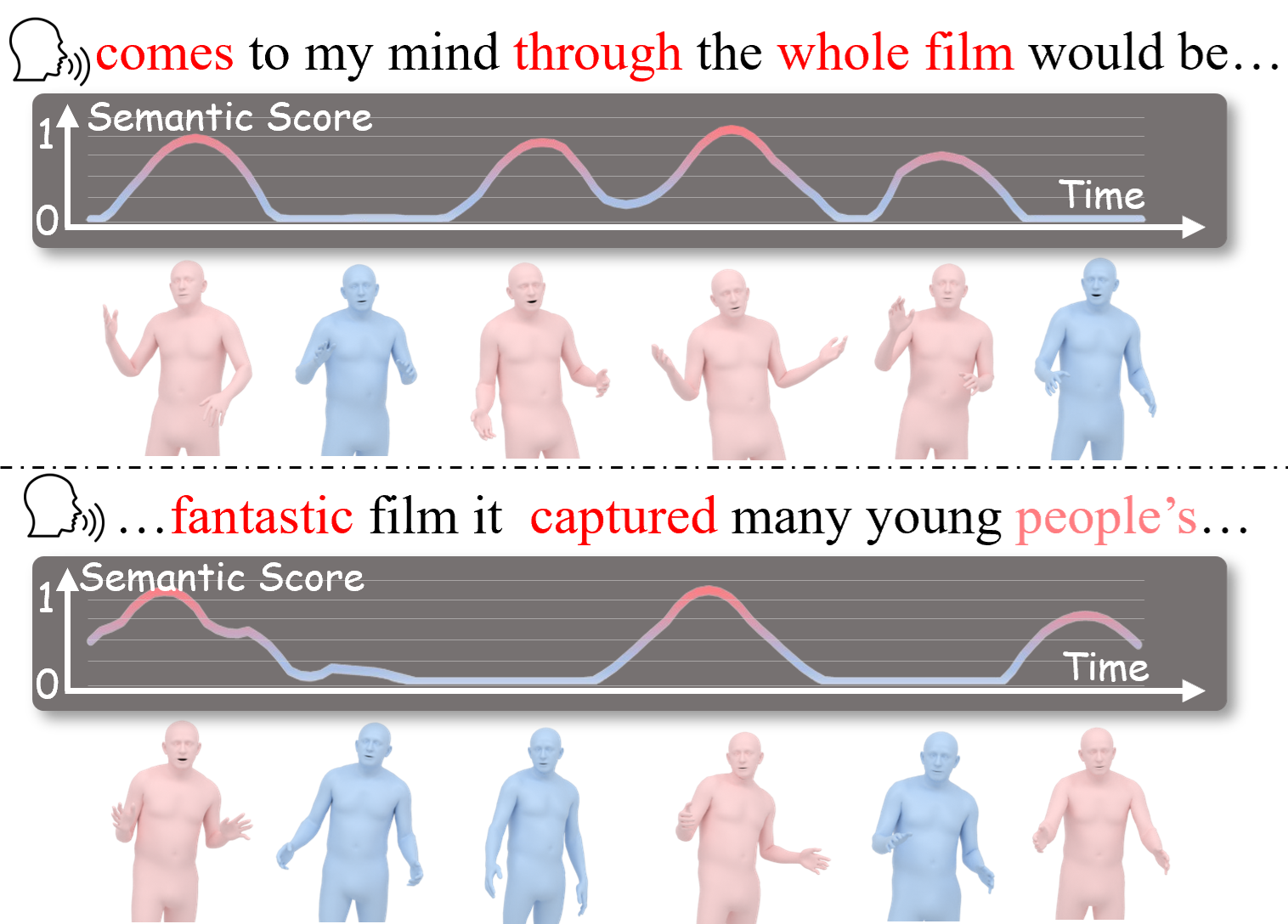
Semantic Emphasis
The central design choice is not to make every frame more expressive. Instead, SemTalk learns when the speech contains a phrase that should trigger stronger, sparse gestures.
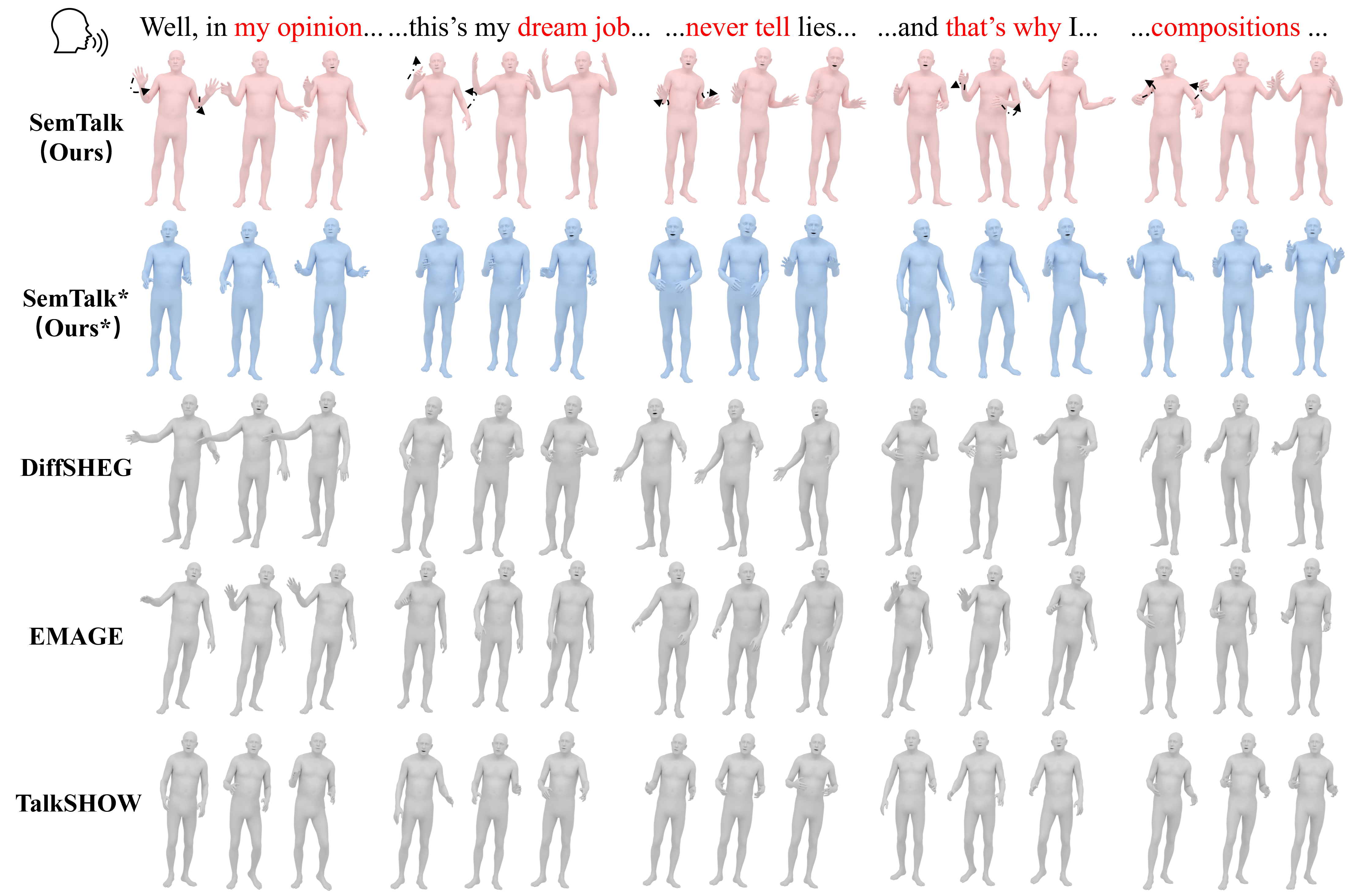
Qualitative Results
The visual comparisons show what the semantic branch changes: gestures become more intentional at meaningful words while staying stable during ordinary speech.


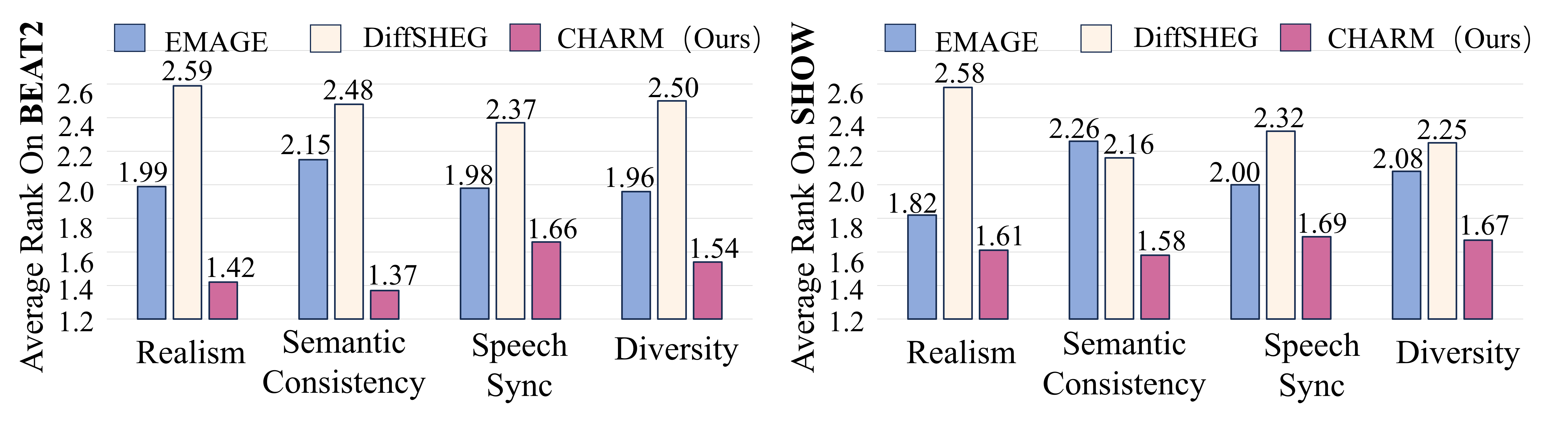
Quantitative Results
Lower is better for FGD, MSE, and LVD; higher is better for BC and DIV. SemTalk gives the best motion-distribution score on both BEAT2 and SHOW while keeping strong beat consistency.
| Method | FGD lower | BC higher | DIV higher | MSE lower | LVD lower |
|---|---|---|---|---|---|
| CaMN | 6.644 | 6.769 | 10.86 | - | - |
| DSG | 8.811 | 7.241 | 11.49 | - | - |
| TalkSHOW | 6.209 | 6.947 | 13.47 | 7.791 | 7.771 |
| EMAGE | 5.512 | 7.724 | 13.06 | 7.680 | 7.556 |
| DiffSHEG | 8.986 | 7.142 | 11.91 | 7.665 | 8.673 |
| SemTalk | 4.278 | 7.770 | 12.91 | 6.153 | 6.938 |
| Method | FGD lower | BC higher | DIV higher | MSE lower | LVD lower |
|---|---|---|---|---|---|
| CaMN | 22.12 | 7.712 | 10.37 | - | - |
| DSG | 24.84 | 8.027 | 10.23 | - | - |
| Habibie et al. | 27.22 | 8.209 | 8.541 | 145.6 | 47.35 |
| TalkSHOW | 24.43 | 8.249 | 10.98 | 139.6 | 45.17 |
| EMAGE | 22.12 | 8.280 | 12.46 | 136.1 | 42.44 |
| DiffSHEG | 24.87 | 8.061 | 10.79 | 139.0 | 45.77 |
| SemTalk | 20.18 | 8.304 | 11.36 | 134.1 | 39.15 |
BibTeX
@inproceedings{zhang2025semtalk,
title={SemTalk: Holistic Co-speech Motion Generation with Frame-level Semantic Emphasis},
author={Zhang, Xiangyue and Li, Jianfang and Zhang, Jiaxu and Dang, Ziqiang and Ren, Jianqiang and Bo, Liefeng and Tu, Zhigang},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={13761--13771},
year={2025}
}