StreamTalk: Streaming Co-Speech Gesture Generation with Key-Pose Anchoring
Abstract
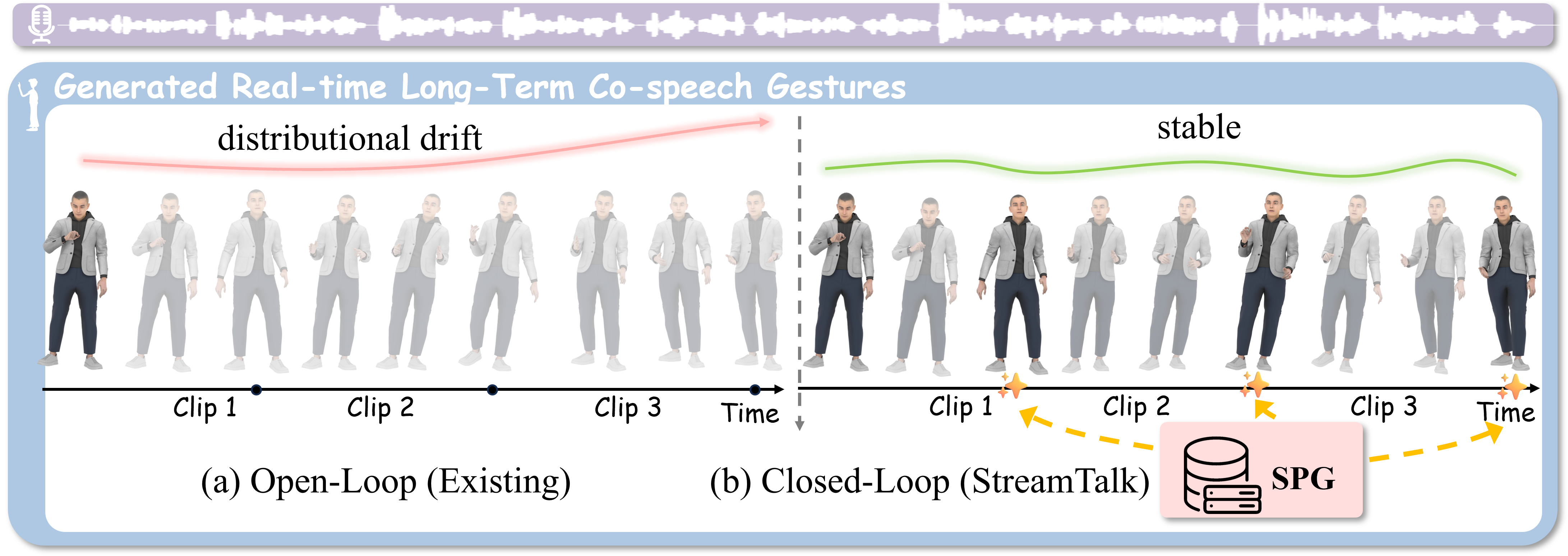
Real-time co-speech gesture generation must produce 3D motion clip by clip as speech streams in. Existing streaming methods are fundamentally open-loop: each clip is synthesized from past context and directly passed to the next window, so small errors compound into long-horizon distributional drift. StreamTalk addresses this with a closed-loop streaming framework. At inference time, Streaming Pose-Guided Generation (SPG) first generates a coarse clip, retrieves a plausible tail key pose from a speaker-specific motion database, and refines the clip with this destination anchor before moving to the next window. During training, Stochastic Anchor Masking (SAM) teaches the model to inpaint complete motion from sparse boundary anchors, while a part-aware DiT separates hands, body, and translation streams. On BEAT2, StreamTalk improves motion quality, suppresses minute-scale drift, and runs in real time.
Demo
Method
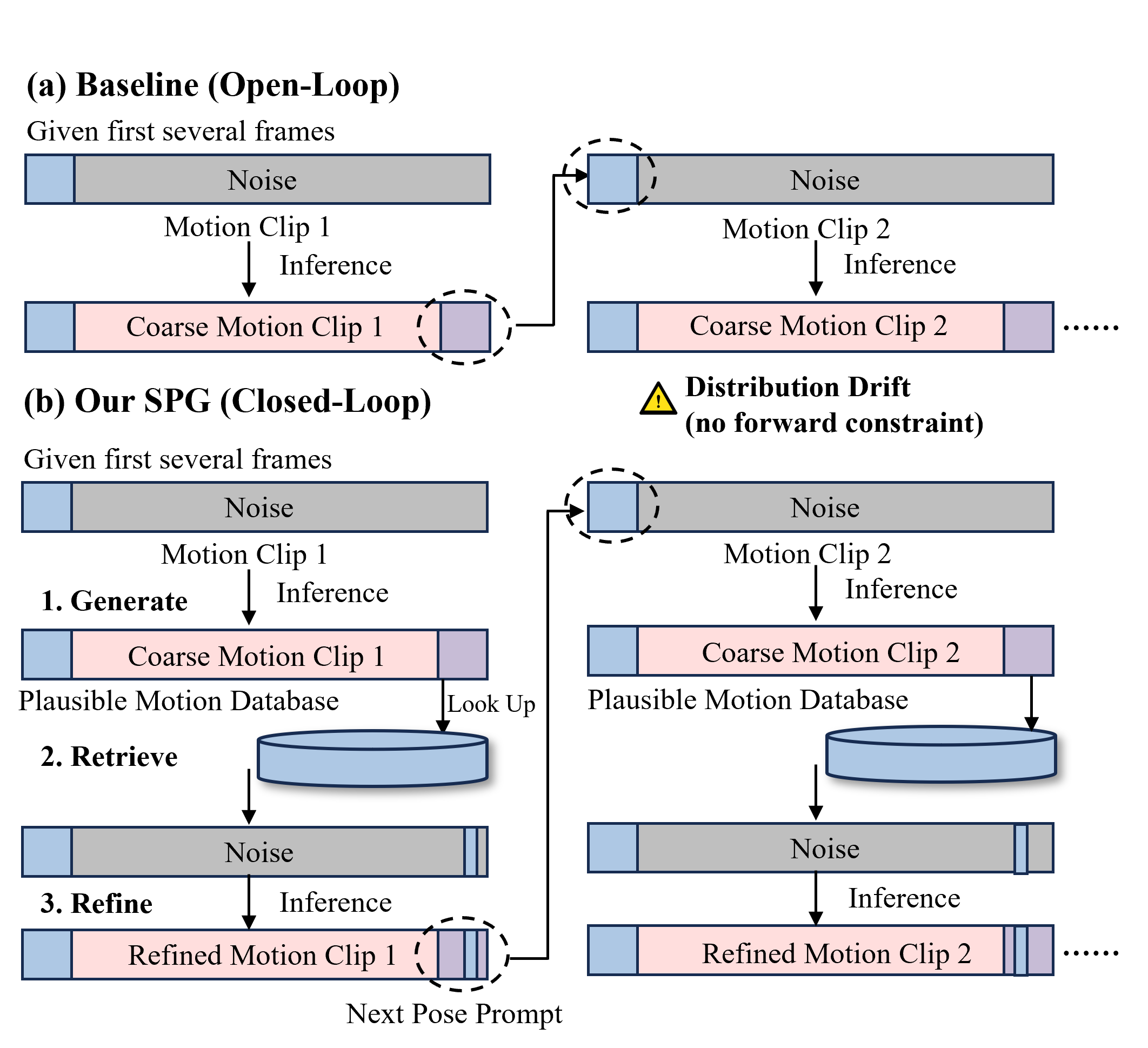
StreamTalk uses a generate-retrieve-refine cycle to periodically pull streaming motion back toward a plausible pose distribution.
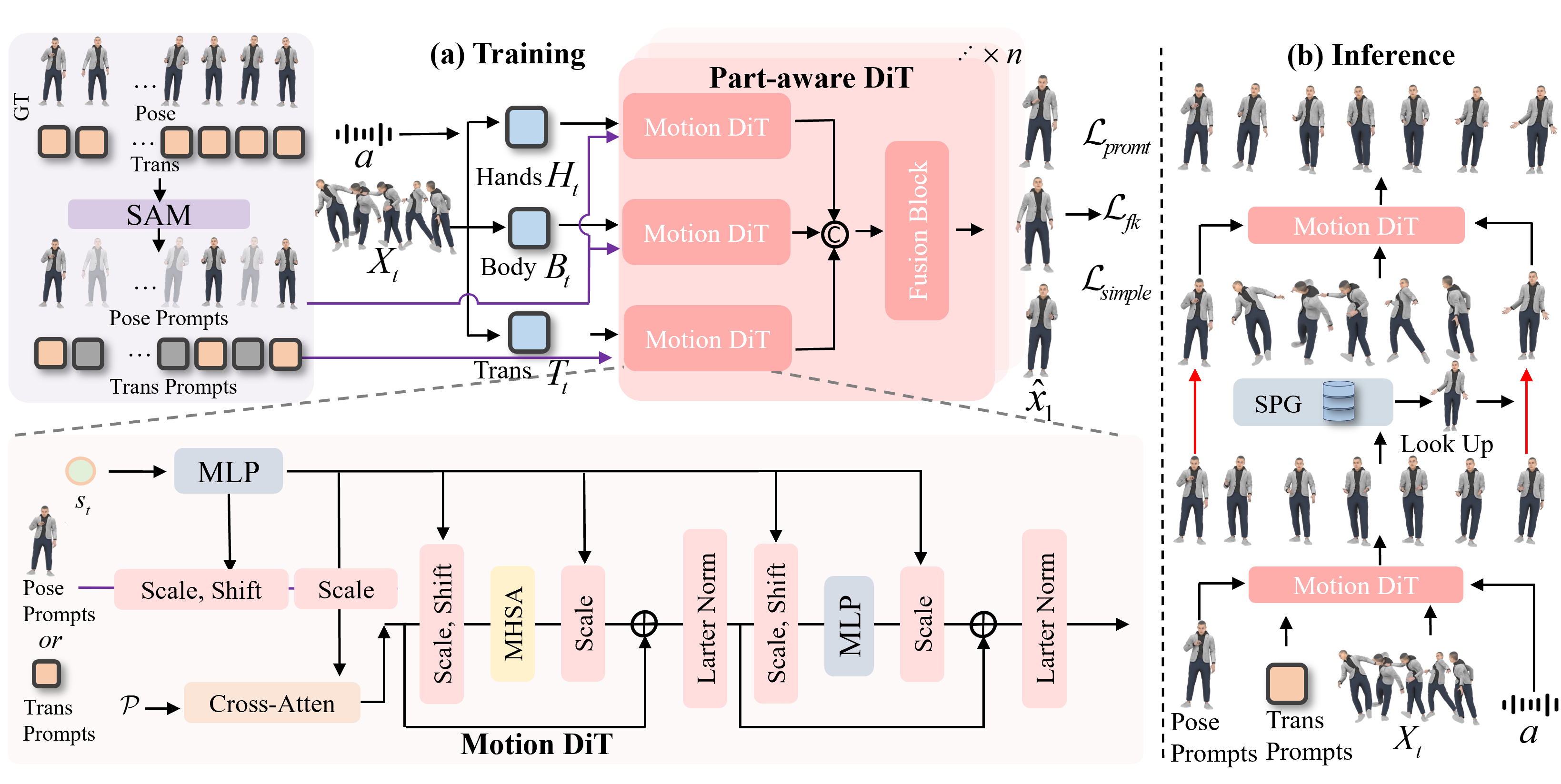
Closed-Loop Streaming
Core Quantitative Results
The key number is FGD: lower FGD means the generated gesture distribution is closer to real human motion. StreamTalk achieves the best FGD on both the single-speaker streaming setting and the harder all-speaker setting, while keeping beat consistency and diversity close to the ground truth.
| Method | FGD lower | BC near GT | DIV near GT |
|---|---|---|---|
| GT | - | 0.703 | 11.97 |
| EMAGE | 0.551 | 0.772 | 13.06 |
| RAG-GESTURE | 0.808 | 0.734 | 11.97 |
| EchoMask | 0.462 | 0.774 | 13.37 |
| GestureLSM | 0.409 | 0.714 | 13.42 |
| SemTalk | 0.428 | 0.777 | 12.91 |
| StreamTalk | 0.383 | 0.704 | 13.18 |
| Method | FGD lower | BC near GT | DIV near GT |
|---|---|---|---|
| GT | - | 0.477 | 7.29 |
| CaMN | 0.512 | 0.200 | 5.58 |
| EMAGE | 0.692 | 0.284 | 6.06 |
| HoloGest | 0.646 | 0.803 | 13.53 |
| RAG-GESTURE | 0.487 | 0.514 | 9.94 |
| StreamTalk | 0.293 | 0.616 | 7.27 |
BC and DIV are interpreted relative to the ground-truth row rather than simply maximized. The all-speaker result is especially important because it shows that the retrieved anchors do not only help one speaker; they generalize across identities.
What Makes It Work?
The gains come from matching training and inference: SAM teaches the model to use sparse anchors, and SPG supplies those anchors during streaming inference. Either piece alone helps less than the full closed-loop system.
| Method | 1-Spk FGD | 1-Spk BC | 1-Spk DIV | All FGD | All BC | All DIV |
|---|---|---|---|---|---|---|
| GT | - | 0.703 | 11.97 | - | 0.477 | 7.29 |
| StreamTalk base | 0.478 | 0.716 | 12.30 | 0.391 | 0.621 | 7.21 |
| + SAM | 0.503 | 0.747 | 13.72 | 0.379 | 0.613 | 7.31 |
| + SPG | 0.455 | 0.695 | 14.24 | 0.353 | 0.607 | 7.49 |
| + SAM and SPG | 0.383 | 0.704 | 13.18 | 0.293 | 0.616 | 7.27 |
| Variant | FGD lower | BC near GT | DIV near GT |
|---|---|---|---|
| GT | - | 0.703 | 11.97 |
| Random anchor | 0.673 | 0.743 | 13.12 |
| Retrieved anchor | 0.503 | 0.747 | 12.57 |
| Retrieved + linear refinement | 0.471 | 0.753 | 12.31 |
| Retrieved + StreamTalk refinement | 0.383 | 0.704 | 13.11 |
| Position | Number | FGD lower | BC near GT | DIV near GT |
|---|---|---|---|---|
| Random | 8 | 0.601 | 0.759 | 13.51 |
| Random | 4 | 0.540 | 0.716 | 13.43 |
| Random | 1 | 0.426 | 0.715 | 13.05 |
| Middle | 1 | 0.408 | 0.693 | 13.55 |
| Tail | 4 | 0.443 | 0.700 | 13.15 |
| Tail | 1 | 0.383 | 0.704 | 13.18 |
A random anchor hurts because an arbitrary pose can point the motion in the wrong direction. A retrieved tail anchor works because drift is mainly a destination problem: the clip needs one plausible waypoint near its boundary, not dense constraints at many frames.
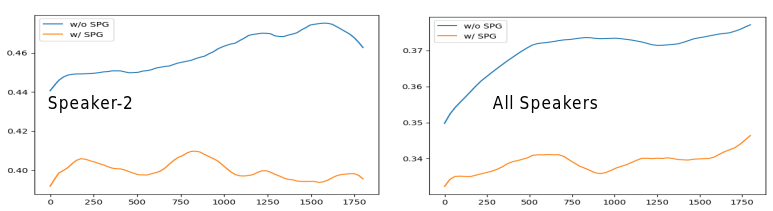
Long-Horizon Stability
StreamTalk is designed for streaming, so we care not only about a short clip looking good, but also whether quality decays after many clip-to-clip transitions.
| Method | VEL lower | ACC lower |
|---|---|---|
| GT | 0.0 | 0.0 |
| EMAGE | 2.40e2 | 4.03e2 |
| GestureLSM | 2.33e2 | 4.30e2 |
| SemTalk | 2.28e2 | 3.58e2 |
| StreamTalk | 2.15e2 | 2.33e2 |
| Window | w/o SPG mean | w/o SPG std | w/ SPG mean | w/ SPG std |
|---|---|---|---|---|
| 70 | 0.4600 | 0.0097 | 0.4000 | 0.0044 |
| 80 | 0.4600 | 0.0149 | 0.4000 | 0.0042 |
| 90 | 0.4600 | 0.0167 | 0.4000 | 0.0033 |
| 100 | 0.4600 | 0.0150 | 0.4000 | 0.0025 |
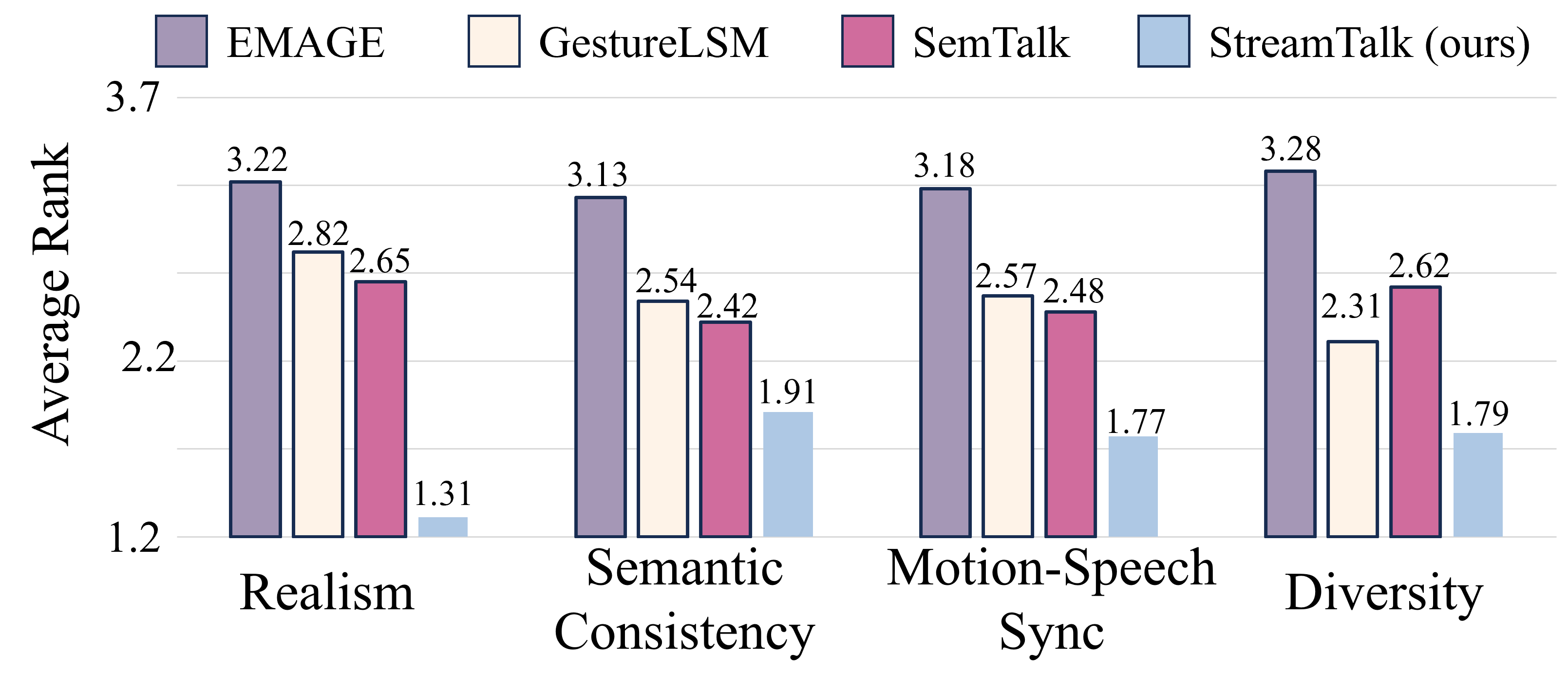
Qualitative and User Study
The tables show distribution-level improvements; the visual comparison explains what those numbers correspond to: smoother transitions, fewer frozen poses, and more stable arm spacing across long speech.

BibTeX
@inproceedings{zhang2026streamtalk,
title={StreamTalk: Streaming Co-Speech Gesture Generation with Key-Pose Anchoring},
author={Zhang, Xiangyue and Li, Jianfang and Zhang, Jiaxu and Yang, Kaixing and Hoi, Steven},
booktitle={European Conference on Computer Vision},
year={2026}
}