PersonaGesture: Single-Reference Co-Speech Gesture Personalization for Unseen Speakers
📋 Abstract
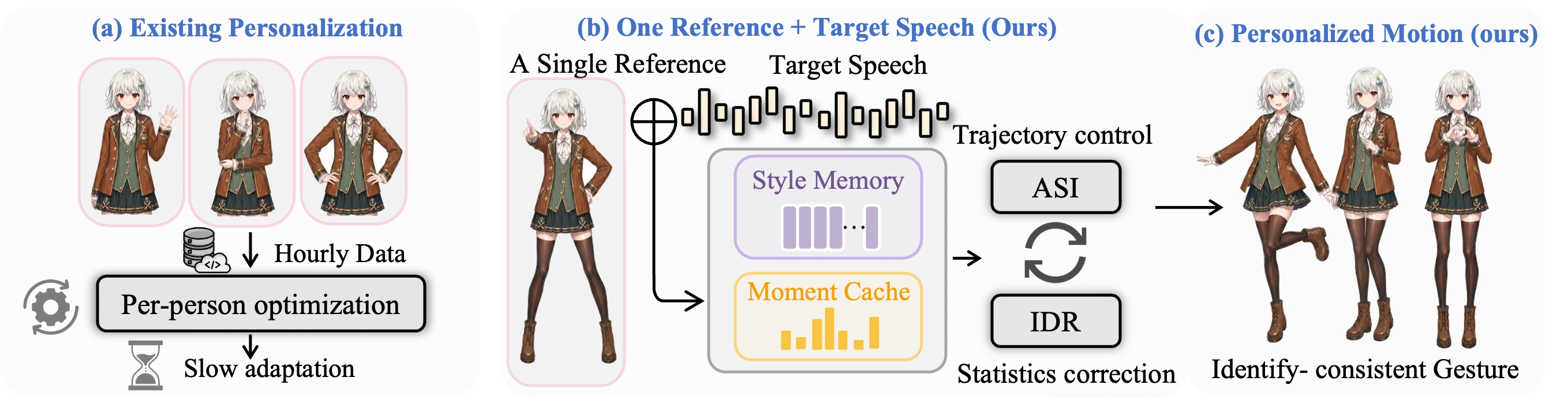
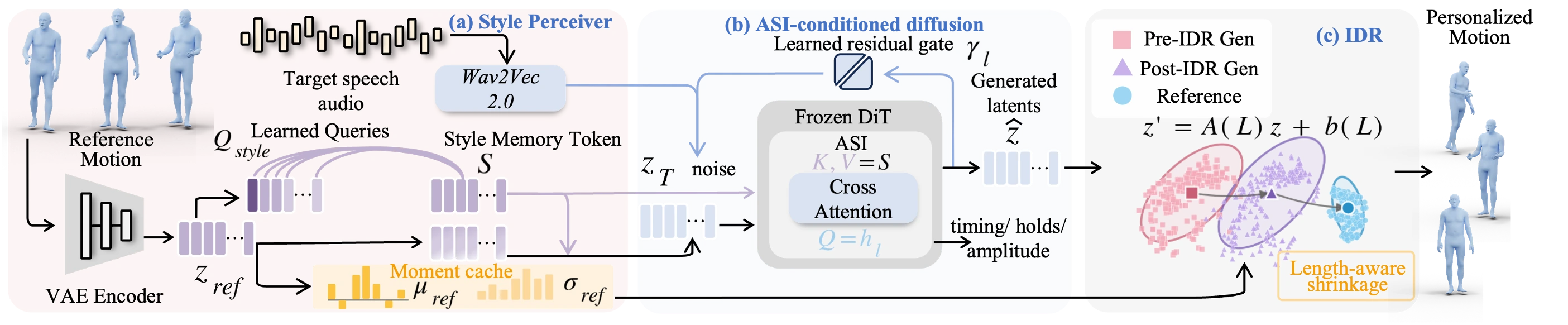
We propose PersonaGesture, a diffusion-based pipeline for single-reference co-speech gesture personalization of unseen speakers. Given target speech and one motion clip from a new speaker, the model must synthesize gestures that follow the new utterance while retaining speaker-specific pose choices, without per-speaker optimization. PersonaGesture separates temporal identity evidence from residual statistic correction through two components: Adaptive Style Infusion (ASI) injects compact speaker-memory tokens into denoising, while Implicit Distribution Rectification (IDR) applies a length-aware latent-space moment correction estimated from the same reference. Across BEAT2 and ZeroEGGS, PersonaGesture improves unseen-speaker personalization over collapsed style codes, full-reference attention, and one-clip finetuning.
🎬 Video
🏗️ Framework
PersonaGesture uses one reference clip as identity evidence, not as a trajectory template for the target speech.
🎨 Qualitative Results
Unseen-speaker BEAT2 examples under the same speech and reference protocol.


📊 Core Quantitative Results
Main unseen-speaker BEAT2 comparison with published baselines adapted from one reference.
| Method | Seen FGD ↓ | Unseen FGD ↓ |
|---|---|---|
| EMAGE | 0.551 | 3.726 |
| SemTalk | 0.428 | 5.687 |
| GestureLSM | 0.409 | 3.176 |
| PersonaGesture | 0.393 | 0.371 |
| Configuration | FGD ↓ | SFD ↓ | ExtStyle ↑ |
|---|---|---|---|
| Stage-2 null-style prior | 0.472 | 2.85 | 36.4% |
| SimpleRef-Attn + gate + IDR | 0.413 | 2.55 | 78.2% |
| Meanpool style-code + IDR | 0.868 | 6.91 | 42.5% |
| FullSeq-RefAttn + IDR | 0.576 | 5.74 | N/A |
| LoRA-TTA r=8 | 0.452 | 2.68 | N/A |
| PersonaGesture ASI only | 0.456 | 2.80 | 77.3% |
| PersonaGesture IDR only | 0.436 | 2.62 | 81.8% |
| PersonaGesture length-aware α(L) | 0.371 | 2.50 | 84.6% |
🔬 Component Diagnostics
ASI and IDR play different roles: speaker memory shapes denoising-time motion, while IDR performs conservative residual moment correction.

🧪 Reference Length and Identity Controls
Length-aware IDR prevents short-reference over-correction, and wrong-speaker references degrade performance as expected.

| Reference | FGD ↓ | SFD ↓ |
|---|---|---|
| Stage-2 null-style prior | 0.745 | 3.18 |
| Default same-speaker | 0.524 | 2.43 |
| Random same-speaker | 0.547 | 2.50 |
| Wrong-speaker | 1.038 | 4.65 |
👥 User Study
Participants ranked naturalness, audio-gesture synchronization, and similarity to a shown speaker-style anchor.
📄 BibTeX
@misc{zhang2026personagesture,
title={PersonaGesture: Single-Reference Co-Speech Gesture Personalization for Unseen Speakers},
author={Zhang, Xiangyue and Cai, Yiyi and Li, Kunhang and Yang, Kaixing and Zhou, You and Li, Zhengqing and Chu, Xuangeng and Zhang, Jiaxu and Liu, Haiyang},
year={2026},
eprint={2605.06064},
archivePrefix={arXiv},
url={http://arxiv.org/abs/2605.06064}
}