Publications
Check the latest through Google Scholar.
Open-Source Systems
-
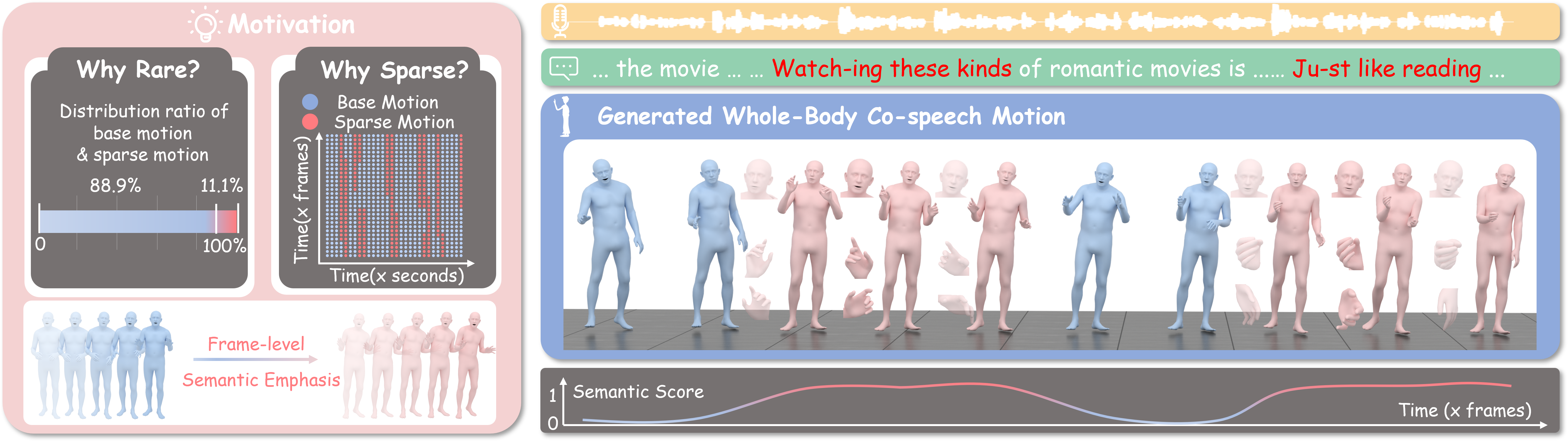
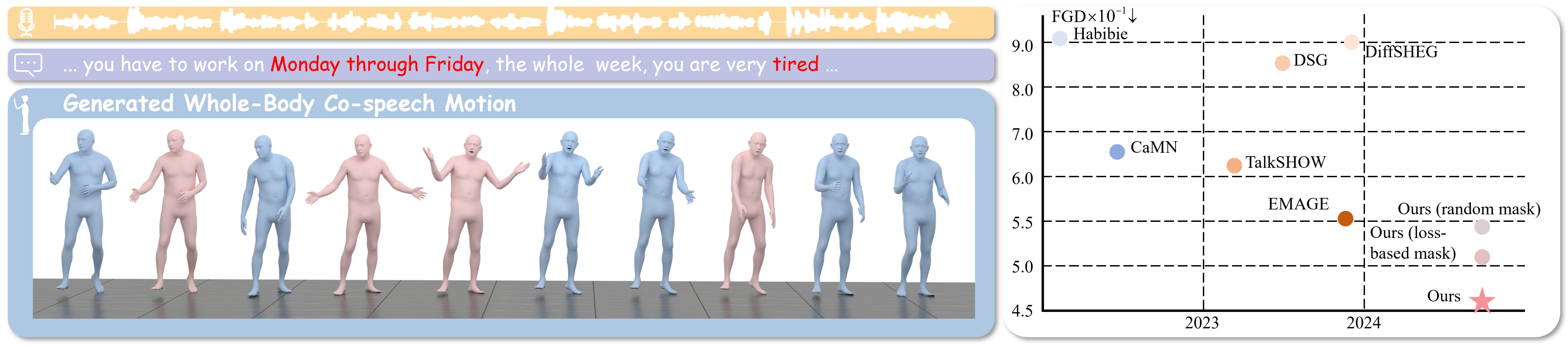
 Technical ReportDeep Researcher Agent: An Autonomous Framework for 24/7 Deep Learning Experimentation with Zero-Cost MonitoringarXiv preprint arXiv:2604.05854, 2026
Technical ReportDeep Researcher Agent: An Autonomous Framework for 24/7 Deep Learning Experimentation with Zero-Cost MonitoringarXiv preprint arXiv:2604.05854, 2026
2026

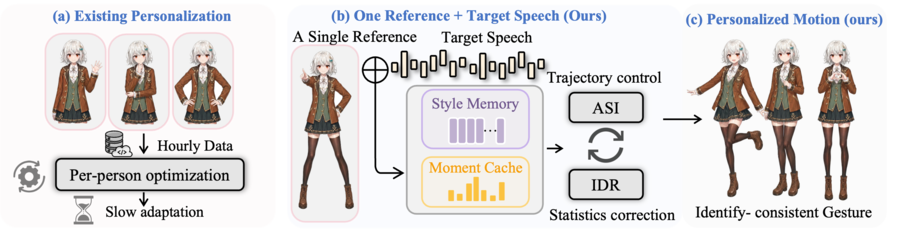
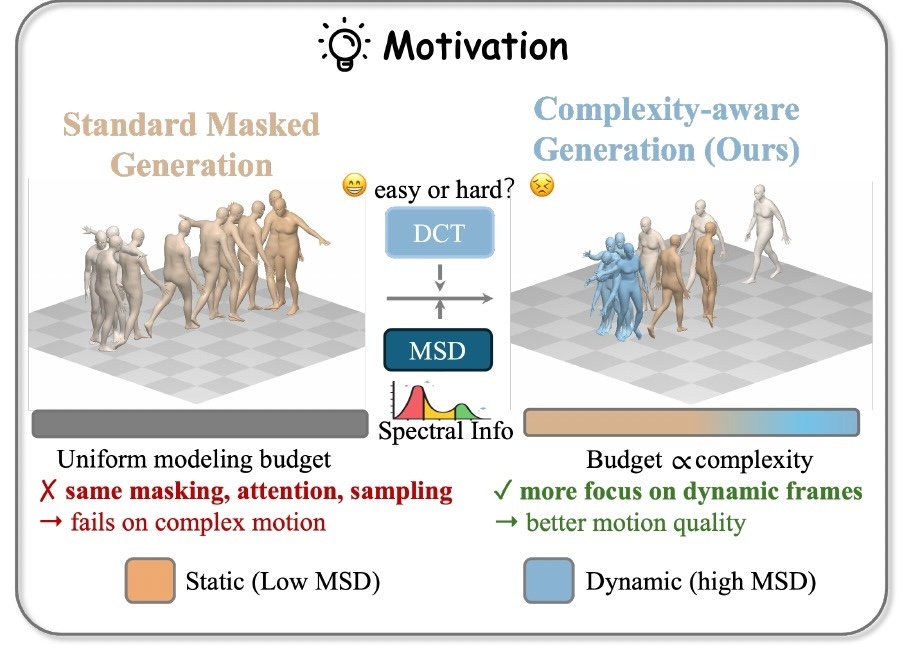
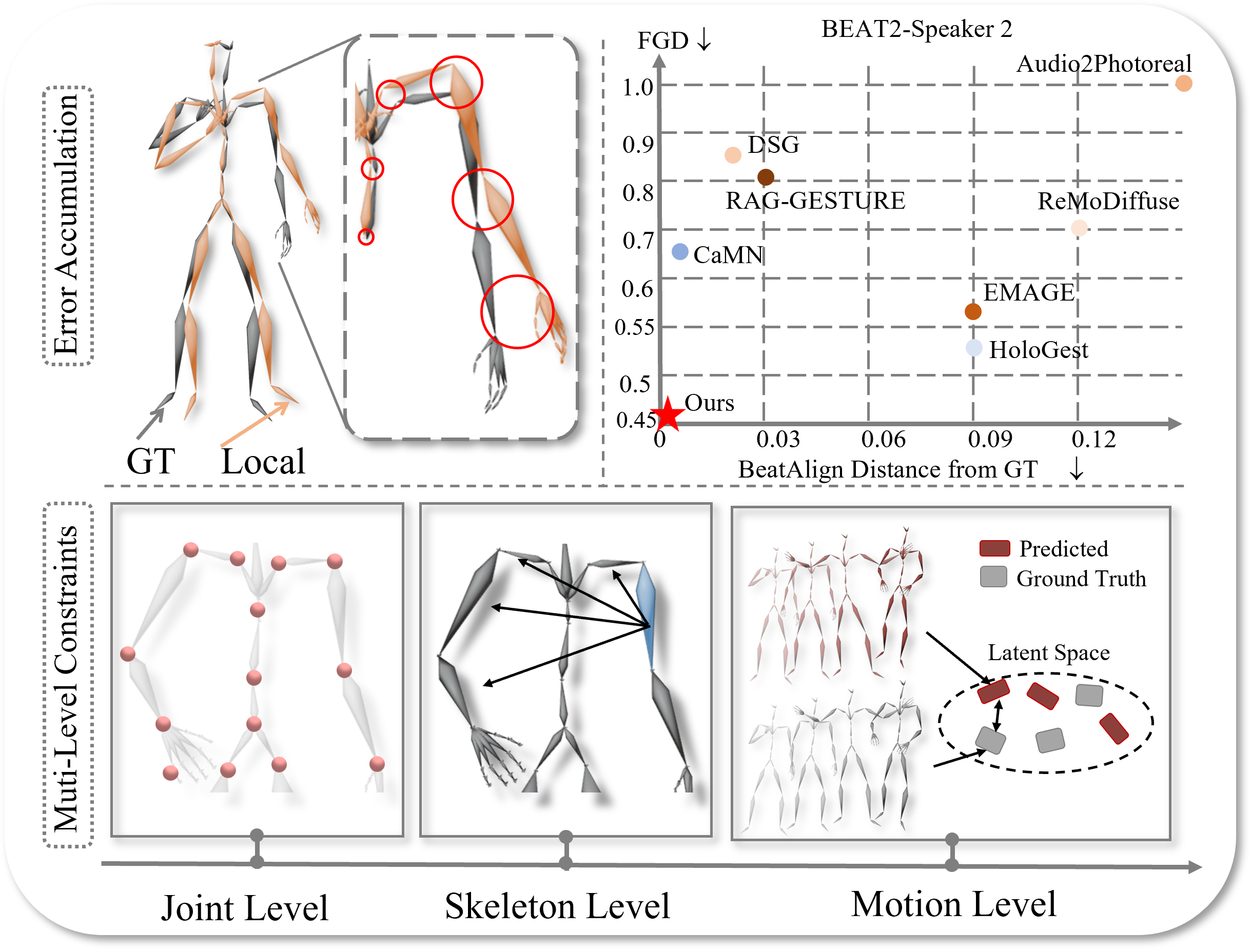

2025
-
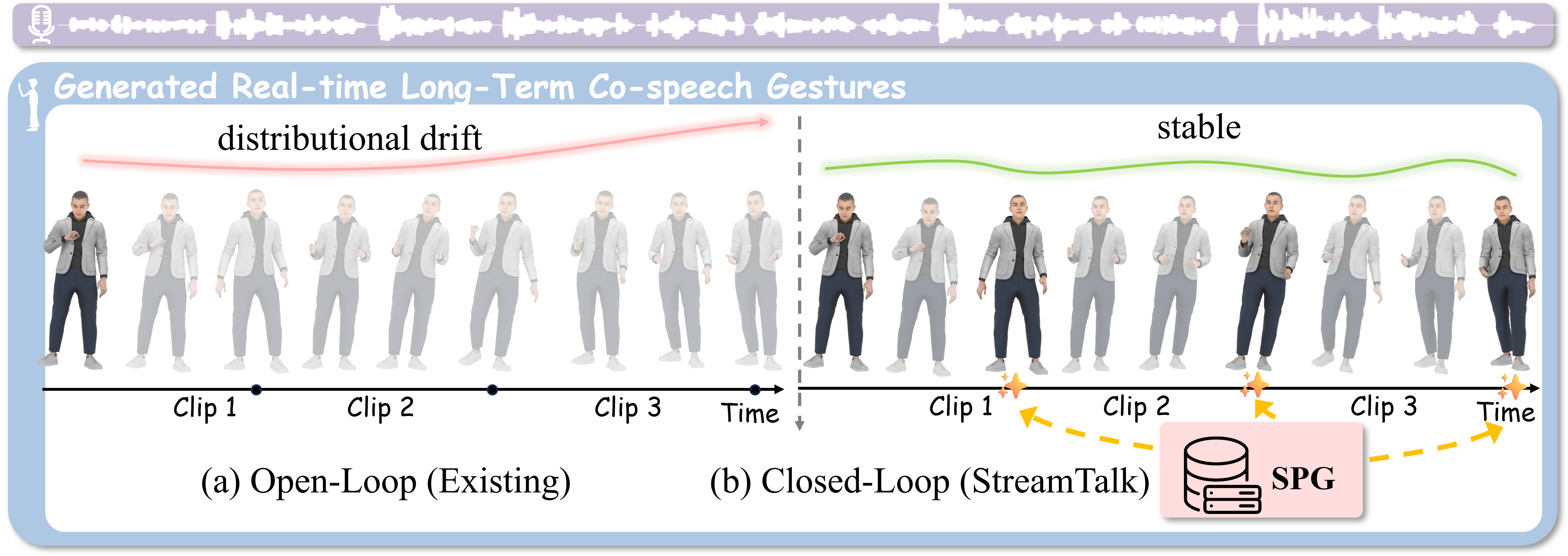
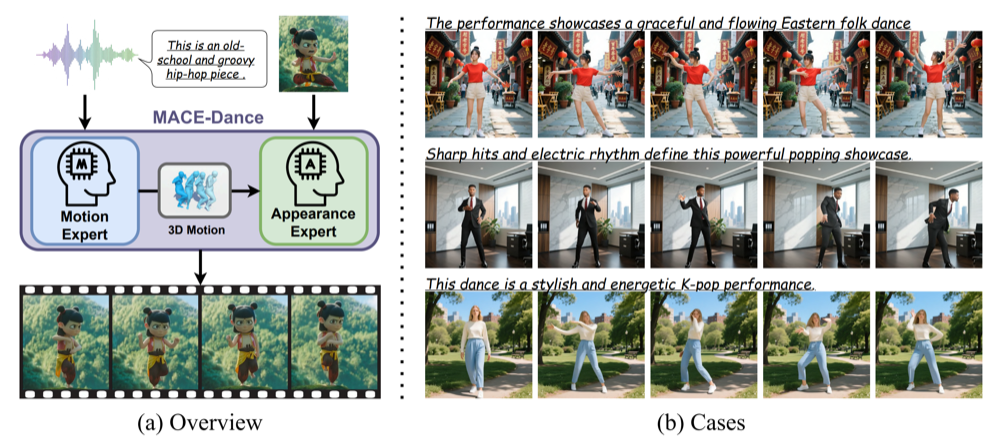
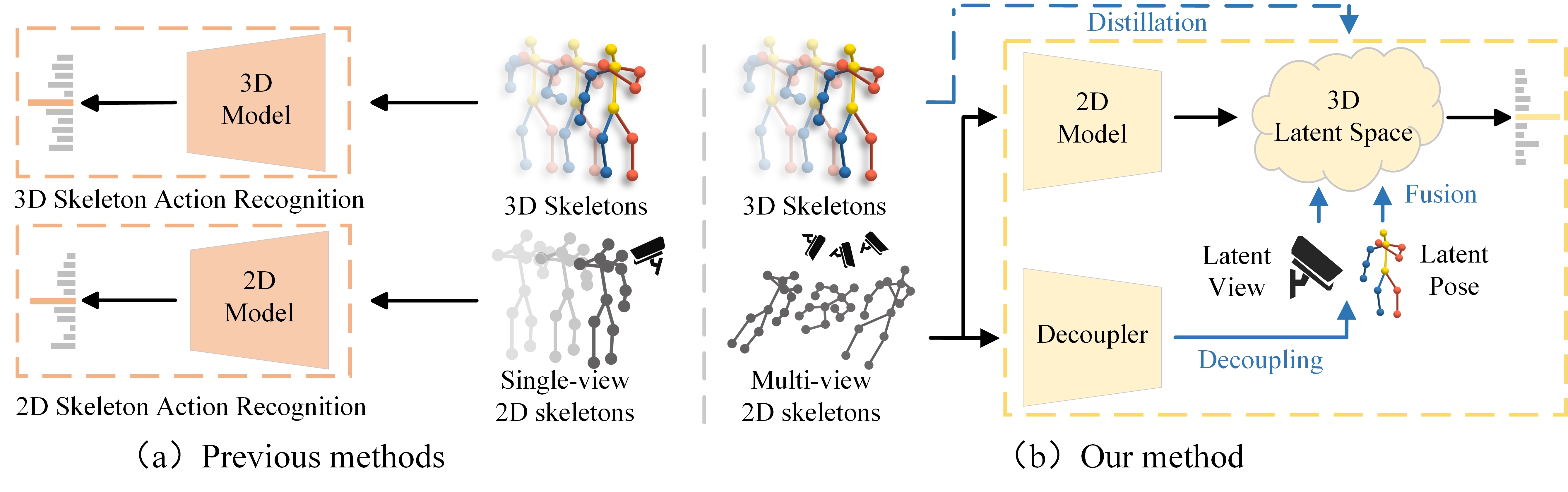 🔥 T-CSVT 2025Robust 2D Skeleton Action Recognition via Decoupling and Distilling 3D Latent FeaturesIEEE Transactions on Circuits and Systems for Video Technology (T-CSVT), 2025
🔥 T-CSVT 2025Robust 2D Skeleton Action Recognition via Decoupling and Distilling 3D Latent FeaturesIEEE Transactions on Circuits and Systems for Video Technology (T-CSVT), 2025